
ABOUT ML Reference Document

Section 2: Literature Review (Current Recommendations on Documentation for Transparency in the ML Lifecycle)
Section 2: Literature Review (Current Recommendations on Documentation for Transparency in the ML Lifecycle)
2.1 Demand for Transparency and AI Ethics in ML Systems
2.1 Demand for Transparency and AI Ethics in ML Systems
Transparency involves making the properties, purpose, and origin of a system clear and explicit to users, practitioners, and other impacted stakeholders. Transparency is valuable for many purposes. Not only can transparency help these groups to understand under what conditions it is appropriate to use the systems, transparency is a foundation for both internal accountability among the developers, deployers, and API users of an ML system and external accountability to customers, impacted non-users, civil society organizations, and policymakers.
Machine Learning
Deepai.org defines machine learning as an “approach to data analysis that involves building and adapting models, which allows programs to ‘learn’ through experience. Machine learning involves the construction of algorithms that adapt their models to improve their ability to make predictions.”
There exists an inherent and default opaqueness in this approach and the ABOUT ML effort aims to remedy that by bringing transparency to the development process, datasets, and other connections around the model through the use of documentation.
While transparency is also difficult to achieve in software engineering contexts, ML systems may present a special challenge. Because modern ML models encode correlations between inputs and outputs that are learned rather than directly specified by developers, the process within an ML model that leads to a particular outcome will often be highly opaque by default. Since the statistical and algorithmic portions of the ML model can be more difficult to make transparent, this makes it all the more important to bring transparency to the development process, datasets, and other connections around the model.
In recognition of both the importance and challenge of incorporating transparency into their ML systems, many organizations include transparency as a core value in their statements of AI principles. Such statements can be an important first stepFriedman, B, Kahn, Peter H., and Borning, A., (2008) Value sensitive design and information systems. In Kenneth Einar Himma and Herman T. Tavani (Eds.) The Handbook of Information and Computer Ethics., (pp. 70-100) John Wiley & Sons, Inc. https://jgustilo.pbworks.com/f/the-handbook-of-information-and-computer-ethics.pdf#page=104; Davis, J., and P. Nathan, L. (2015). Value sensitive design: applications, adaptations, and critiques. Handbook of Ethics, Values, and Technological Design: Sources, Theory, Values and Application Domains. (pp. 11-40) DOI: 10.1007/978-94-007-6970-0_3. https://www.researchgate.net/publication/283744306_Value_Sensitive_Design_Applications_Adaptations_and_Critiques; Borning, A. and Muller, M. (2012). Next steps for value sensitive design. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’12). (pp 1125-1134) DOI: https://doi.org/10.1145/2207676.2208560 https://dl.acm.org/citation.cfm?id=2208560 toward making transparency a focus of everyone contributing to ML development. Of course, declared AI principles need to be translated into organizational processes and practical requirements for product decisions in order to become actualized. That translation is hard work and relies on building an institution with systems and processes that can enact the principles put forth.
For instance, AI principles released by Google, IBM, Microsoft, and IEEE all include transparency clauses.Pichai, S., (2018). AI at Google: our principles. The Keyword. https://www.blog.google/technology/ai/ai-principles/; IBM’s Principles for Trust and Transparency. IBM Policy. https://www.ibm.com/blogs/policy/trust-principles/; Microsoft AI principles. Microsoft. https://www.microsoft.com/en-us/ai/our-approach-to-ai; Ethically Aligned Design – Version II. IEEE. https://standards.ieee.org/content/dam/ieee-standards/standards/web/documents/other/ead_v2.pdf IEEE specifies that having AI systems “operate in a transparent manner” was a main goal of their release of their “Ethically Aligned Design” recommendations. Microsoft also names transparency as a core value, saying “AI systems should be understandable.” IBM centers their entire principles statement on “Trust and Transparency” and Google, although not explicitly using the term transparency, states: “We will design AI systems that provide appropriate opportunities for feedback, relevant explanations, and appeal. Our AI technologies will be subject to appropriate human direction and control.”
Broader studies analyzing the full scope of AI principle statements including those from governments, NGOs, academia, and industry further reveal a focus on transparency. Of 50 AI principle statements documented through the Linking AI Principles (LAIP) project,Zeng, Y., Lu, E., and Huangfu, C. (2018) Linking artificial intelligence principles. CoRR https://arxiv.org/abs/1812.04814. 94% (47) explicitly mention transparency. Similarly, 87% and 88% of principle statements surveyed in two other concurrent studiesessica Fjeld, Hannah Hilligoss, Nele Achten, Maia Levy Daniel, Sally Kagay, and Joshua Feldman, (2018). Principled artificial intelligence – a map of ethical and rights based approaches, Berkman Center for Internet and Society, https://ai-hr.cyber.harvard.edu/primp-viz.htmlJobin, A., Ienca, M., & Vayena, E. (2019). Artificial Intelligence: the global landscape of ethics guidelines. arXiv preprint arXiv:1906.11668. https://arxiv.org/pdf/1906.11668.pdf reference “transparency.” In fact, transparency is often highlighted as the most frequently occurring principle in these survey studies, and has been named “the most prevalent principle in the current literature.”Jobin, A., Ienca, M., & Vayena, E. (2019). Artificial Intelligence: the global landscape of ethics guidelines. arXiv preprint arXiv:1906.11668. https://arxiv.org/pdf/1906.11668.pdf Insights from representatives of the procurement role highlight the importance of sharing test results as inputs to a request for proposal process to further validate the usefulness of a model.
Documentation
It should be understood that transparency on its own is not sufficient to ensure positive outcomes from the development of ML systems. There are entire other fields and subfields of research on other goals and principles related to ethics in ML systems, such as explainability, interpretability, robustness, traceability, reproducibility, and more. Documentation can enable some of these other goals as well. Documentation directly addresses the goal of transparency but can also provide an infrastructure for making progress towards these other AI ethics goals. For example, questions included in ABOUT ML recommendations can be used to improve reproducibility of an ML system. A full treatment of all of these subfields is not currently included here but there is a great body of literature on each of these topics for interested parties.
Additionally, there are also often downsides and risks associated with transparency.Ananny, M., and Kate Crawford (2018). Seeing without knowing: Limitations of the transparency ideal and its application to algorithmic accountability. New Media and Society 20 (3): 973-989. Certain forms of transparency may infringe upon the privacy of individuals whose data was used to train the system, enable malicious actors to more easily copy or abuse the system, or place ethically minded developers at a competitive disadvantage by leaking valuable secrets. As one simple example, openly publishing the dataset used to train a medical image recognition system may increase transparency but would also constitute an unethical violation of many patients’ privacy.
The presence of these kinds of complexities means that it is both challenging and necessary to translate abstract ethical ideals about transparency into concrete guidelines.Whittlestone, J., Nyrup, R., Alexandrova, A., & Cave, S. (2019, January). The Role and Limits of Principles in AI Ethics: Towards a Focus on Tensions. In Proceedings of the AAAI/ACM Conference on AI Ethics and Society, Honolulu, HI, USA (pp. 27-28). https://www.aies-conference.com/wp-content/papers/main/AIES-19_paper_188.pdf; Mittelstadt, B. (2019). AI Ethics–Too Principled to Fail? https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3391293 Although study after study confirms that meaningful progress cannot be made until ethical ideals are operationalized,Greene, D., Hoffmann, A. L., & Stark, L. (2019, January). Better, nicer, clearer, fairer: A critical assessment of the movement for ethical artificial intelligence and machine learning. In Proceedings of the 52nd Hawaii International Conference on System Sciences. https://scholarspace.manoa.hawaii.edu/handle/10125/59651 the inconsistency with which high-level principles such as transparency are interpreted across different contexts, organizations, and even teams makes it difficult to design consistent practical interventions. The lack of practical theory around these ethical ideals also serves as a roadblock to facilitating outside auditing from interested parties looking to hold AI system developers accountableRaji, I. D., & Buolamwini, J. (2019). Actionable auditing: Investigating the impact of publicly naming biased performance results of commercial ai products. In AAAI/ACM Conf. on AI Ethics and Society (Vol. 1). https://www.media.mit.edu/publications/actionable-auditing-investigating-the-impact-of-publicly-naming-biased-performance-results-of-commercial-ai-products/ and can impede or slow down the responsible deployment of these models.
2.2 Documentation to Operationalize AI Ethics Goals
2.2 Documentation to Operationalize AI Ethics Goals
As discussed above, transparency is a widely adopted AI ethics principle which can also serve as an enabler of other AI ethics goals. There are a number of possible approaches to increasing transparency in ML lifecycles which could include various forms of communication, stakeholder involvement, inclusion of role-based human representatives, use of risk assessment models, dissemination check lists, and auditable taxonomies. For example, techniques from the field of “explainable AI” can in some contexts make the behavior of ML systems easier to explain. Public commitments to abide by particular development principles are another non-technical method of increasing transparency.
The specific focus of this project is on documentation, which we believe is an especially simple and accessible approach to transparency and beyond. Documentation is both an artifact (in this case, a document with details about the ML system, similar to a nutrition label on food) and a process (in this case, a series of steps people follow in order to create the document). Each yields different benefits. Documenting key stages and components of ML lifecycles and sharing this documentation internally and externally can be an effective means of building trust in ML systems. It can also complement other approaches by fostering positive norms and processes for communication ABOUT ML systems, reducing the “black box” nature of these products which are increasingly deployed in ways that impact many people. Documentation provides important benefits even in contexts where full external sharing is not possible. For instance, internal documentation can help to improve communication between collaborating teams. Internal documents also help build employee trust by providing employees with both opportunities to pose ethical objections and with more meaningful understandings of their roles in the creation of end products. It will be important to know and manage which team members will have access to these internal documents.
Incidents
Our working definition for “AI incidents” is the following:
AI incidents are events or occurrences in real life that caused or had the potential to cause physical, financial, or emotional harm to people, animals, or the environment.
This is the basis of the AIID project we are evolving in conjunction with our ABOUT ML documentation efforts and is meant to add to the compendium of resources to support the reduction of harm from AI systems.
Beyond the artifact itself, the process of documentation can support the goal of transparency by prompting critical thinking about the ethical implications of each step in the ML lifecycle and ensuring that important steps are not skipped. Well-functioning internal organizational processes that can support the systematic documentation of every ML system or dataset created can also serve as the infrastructure for ethics review processes, auditing, or other similar initiatives aimed at ensuring the ML systems provide benefits and minimize harm for as many stakeholders as possible.
As a result, the overall process an organization needs to follow and deep dives into the specific transparency documentation questions to address with regards to the ML system are currently among the more well-researched topics in the transparency space. Organizations (including many PAI Partners) have begun to implement recommendations from those publications and such work is beginning to influence procurement processes and regulatory documentation requirements by governments.Algorithmic Impact Assessment (2019) Government of Canada https://www.canada.ca/en/government/system/digital-government/modern-emerging-technologies/responsible-use-ai/algorithmic-impact-assessment.html PAI’s ABOUT ML effort aims to synthesize this research and learnings from previous transparency initiatives into best practices and new norms for documentation on ML lifecycles.
ABOUT ML is beginning with a focus on developing documentation to clarify the details of specific ML systems for the sake of improving the transparency of that system. Note that this differs from the goals of other documentation proposals, which aim to set legally binding restrictionsBenjamin, M., Gagnon, P., Rostamzadeh, N., Pal, C., Bengio, Y., & Shee, A. (2019). Towards Standardization of Data Licenses: The Montreal Data License. arXiv preprint arXiv:1903.12262. https://arxiv.org/abs/1903.12262; Responsible AI Licenses v0.1. RAIL: Responsible AI Licenses. https://www.licenses.ai/ai-licenses, set declarative value statements,See Citation 5 or propose guidelines on systems-level ethical restrictions of use in a more general sense, and beyond the scope of model development and deployment decisions.Safe Face Pledge. https://www.safefacepledge.org/; Montreal Declaration on Responsible AI. Universite de Montreal. https://www.montrealdeclaration-responsibleai.com/; The Toronto Declaration: Protecting the right to equality and non-discrimination in machine learning systems. (2018). Amnesty International and Access Now. https://www.accessnow.org/cms/assets/uploads/2018/08/The-Toronto-Declaration_ENG_08-2018.pdf ; Dagsthul Declaration on the application of machine learning and artificial intelligence for social good. https://www.dagstuhl.de/fileadmin/redaktion/Programm/Seminar/19082/Declaration/Declaration.pdf These other types of documentation may be explored in the future.
Documentation of ML systems is valuable to different stakeholders for different reasons. ML system developers/deployers can use documentation to support efficient practices for refinement, debugging, new team member onboarding, alignment of development and deployment with stated business goals, and many other positive outcomes. ML system procurers can infuse clarity of intention and expectation in requests for proposals as well as statements of work for ML products. Procurement documents are considered an important artifact in the procurement process and several variations can be positively impacted through ML documentation best practices, including requests for quotes, information, and/or bids as well as invitations for bids, purchase orders, and contract agreements. Users of ML system APIs along with experienced end users find value in the clear expression of risk and consequence which can aid in their decisions to use an ML system at the outset. Internal compliance teams and external auditors can shape conversations ABOUT ML impact and liability in order to provide meaningful guidance to organizations attempting deployment. Marketing groups can use documentation to make talking points and other informative tools available to people communicating the work, giving them power to translate what is occurring within an organization effectively and without misinformation.
2.2.1 Documentation as a Process in the ML Lifecycle
2.2.1 Documentation as a Process in the ML Lifecycle
Documentation for ML lifecycles is not simply about disclosing a list of characteristics about the data sets and mathematical models within an ML system, but rather an entire process that an organization needs to incorporate throughout the design, development, and deployment of the ML system being considered.Dobbe, R., Dean, S., Gilbert, T., & Kohli, N. (2018). A Broader View on Bias in Automated Decision-Making: Reflecting on Epistemology and Dynamics. https://arxiv.org/pdf/1807.00553.pdf Incorporating transparency documentation into the build process includes asking and answering questions about the impact of the ML system and provides an internal accountability mechanism via the documented answers which can be referenced at a later date. In order to be effective, this non-trivial process needs resourcing, executive sponsorship, and other forms of institutional support to become and remain a sustainable and integral part of every project.Wagstaff, K. (2012). Machine learning that matters. https://arxiv.org/pdf/1206.4656.pdf ; Friedman, B., Kahn, P. H., Borning, A., & Huldtgren, A. (2013). Value sensitive design and information systems. In Early engagement and new technologies: Opening up the laboratory (pp. 55-95). Springer, Dordrecht. https://vsdesign.org/publications/pdf/non-scan-vsd-and-information-systems.pdf
2.2.2 Key Process Considerations for Documentation
2.2.2 Key Process Considerations for Documentation
Because documentation is as much a process as it is a set of artifacts, transparency and documentation need to be an explicit part of the discussion at each step of the workflow. This is not to say that organizations just now beginning to do the work of ML documentation for processes and products cannot retroactively perform these tasks, but some information may be irretrievably lost between development and documentation if they are not pursued in parallel. The work can begin at the beginning during planning and requirements-gathering and flow through every stage of data/model specification to deployment and monitoring. It can also be implemented as a revisionary act to gird up previously undocumented or inadequately transparent efforts. What follows is a summary of the steps involved in the process and an overview of the challenges involved at each stage. As mentioned in the previous section, these steps are not necessarily sequential and considerations at each step may come into play repeatedly and at various points in the ML system lifecycle.
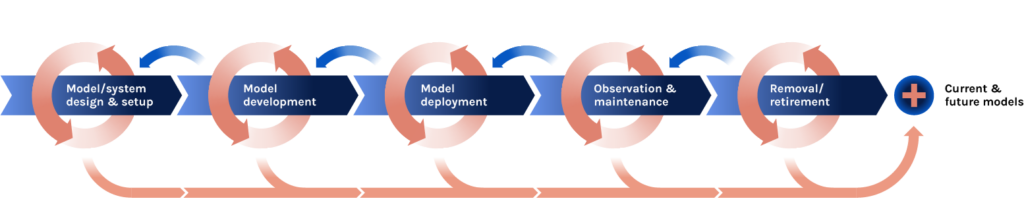
Figure 2.1 Overview of ML system lifecycle
Methods for Inclusion
Every step of the ML lifecycle needs to consider multiple perspectives, ideally through actively including individuals representing different stakeholders in the conversations but recognizing that teams must work within the constraints of time and resources. Key stakeholders are both internal (e.g., different departments, like Policy, Legal, Operations, and Sales, or different roles, like UX designers, engineers, product managers, directors, etc.) and external (e.g., civil society organizations, academia, policymakers, and people impacted by the technology). ML systems often operate as components of products and services that impact a diverse range of communities, including many whose viewpoints are rarely considered by technology developers. A special effort should thus be made to consult highly impacted but otherwise not consulted communities during each phase of model and system development in order to prevent rolling out a product with unanticipated adverse effects. Documenting how feedback was collected and incorporated throughout this process may serve as a reminder to complete this important step.
This documentation process begins in the ML system design and set up stage, including system framing and high-level objective design. This involves contextualizing the motivation for system development and articulating the goals of the system in which this system is deployed, as well as providing a clear statement of team priorities and objectives throughout the system design process. Prior to developing a particular ML system, one must first design the context in which the model or models will be incorporated.Dobbe, R., Dean, S., Gilbert, T., & Kohli, N. (2018). A Broader View on Bias in Automated Decision-Making: Reflecting on Epistemology and Dynamics. https://arxiv.org/pdf/1807.00553.pdf This begins with aligning the team and institutional setting to adequately resource the transparency process, and involves investing in transparency as a design value. Depending on the organization, this may require conversations and executive buy-in at multiple levels or a simple commitment and adding this as a performance metric or objective and key result (OKR). Before transparency can be achieved in a project, it must first be agreed upon as a prioritized design value for the team and organization involved. For this to be achieved, a clear-headed conversation about the ML product or system goals is required, including clarifying system objectives through the consideration of how the specifications and requirements of the system serve the declared goals, and what deployment standards are, including declaring sensitive use cases and what limitations and oversight would be needed for those. Many teams are needed for this conversation, likely a combination of engineering, product, legal, business, operations, user experience design, etc. In some cases, it is also important to bring in external perspectives like impacted parties to consult during this phase. The institutional setting and norms that support AI ethics practices such as documentation for transparency is an area of active research, and this section will be expanded in the future to reflect that emerging body of knowledge.
After documenting the context in which the system is being developed and why it exists, the next step occurs during planning for the ML development pipeline by creating a detailed and well-documented overview of the components of the ML development pipeline — from the data used to train the system to the specifics of the system architecture and output characteristics. Now that the system requirements and goals have been specified, the questions for transparency move towards the tactical for datasets, models, and the overall systems. This stage involves identifying which datasets will be constructed, which systems will be built, and how all of them will be connected. There are often complications at the system level that arise from connecting complex datasets, models, and systems which impact additional stakeholders. This is the time to reflect about those and have a dedicated meeting together to identify what might go wrong and mitigation strategies to build into the system ahead of time (also known as a premortem). The process involves documentation on data, model and system-level details.
Data Documentation
Data documentation is an incredibly important consideration and often a key challenge. As a driving factor of system development, custom or task-specific datasets are created, collected, or developed for different uses, such as testing, benchmarking, etc. It is thus important to outline explicitly the intent and limitations behind the datasets involved in the testing and training of mathematical models within the system, as well as to disclose any other information, such as its provenance, relevant to the wider use of this dataset. Model documentation involves a look at the characteristics of the intent behind the development of the model, an account of decisions relevant to system reproducibility (including algorithmic details and comments on the training process), motivations behind which object functions were considered and chosen, and risks associated with the chosen model architecture. System documentation discusses how datasets and mathematical models within the system are connected, what potential unforeseen complications may arise from those connections, how those complications are accounted for, and how the system will be used. This is the time to outline the ML requirements for the system and discuss the alignment of these requirements to the stated goals and design values of the system.
Before releasing an ML system into the world, teams must ensure the system works as intended. It is important to consider risks from unintended uses — either via misuse or use in unintended contexts — and set forth a series of safeguards to minimize harm to those most affected by the ML system. This can take the form of system testing. The selection of appropriate and fair evaluation criteria for measuring system behaviour and performance is an integral step in determining the effectiveness of an ML system. This should be done before choosing a model architecture to keep from biasing the evaluation criteria, except additional testing of known risks and limitations of an architecture. Making performance metrics and evaluation procedures clear and comprehensible will ensure an adequate understanding of the considerations involved before the decision to deploy the system or scale its use to a certain scope. Another consideration is system maintenance and updates. After an ML system is released, it needs to be monitored and maintained to ensure expected performance and to check that all safeguards are working correctly. Documenting the planned and implemented monitoring process includes expected performance, possibly broken down by subgroups, who does the monitoring and maintenance, what monitoring systems are in place, how they operate, and update and release timelines or trigger events.
MLLC vs. SDLC
Dblue.ai distinguishes between the machine learning lifecycle (MLLC) and the software development lifecycle (SDLC) by noting that software is:
“built based on the requirements provided during the first phase of SDLC. But in machine learning, a model is built based on a specific dataset […] [T]he underlying characteristics of the data might change and your models may not be giving the right result.”
Additionally, important distinctions in drift, maintenance, and monitoring between the two highlight the need for differences in documentation cadence and audience.
The preceding paragraphs discussed how documentation would be incorporated into the development process the first time an ML system is created. The upfront cost of setting up a documentation process is likely to be much more resource- and time-intensive than future updates because of the startup cost to unearth previously undocumented assumptions, integrate user-friendly tools to reduce friction for creating documentation, and train people to include this step into their workflows. However, these initial costs will no longer be present to update documentation after the initial investment. For parts of the documentation that may need more frequent changes (e.g., model, training, testing, etc.), ideally a shared process could be developed to make these updates semi-automatic (similar to Javadoc for the JAVA programming language or docstrings in Python). How and when to update documentation remains an open question of increasing importance since many models are continuously updated with new data. There is not yet consensus on what changes merit a documentation update and which portions of the documentation must be updated each time. To be clear, this statement is relevant to the ML documentation process that is distinct from the general software development lifecycle (SDLC) in many important ways. The discussion should be mindful to balance the time and resources required to produce the update with the actual value of the updated information to avoid creating a documentation process that is too daunting to maintain.
Note that much of the documentation process outlined can and should take place before a single line of code is written. However, the tenets expressed in the ABOUT ML Reference Document are applicable to organizations attempting to perform retrospective reviews of development in an effort to reverse-engineer a set of meaningful documents surrounding both the process and product. This is similar to the design phase of large-scale experiments and clinical trials, where the protocol, statistics plan, and case report form where data are collected are all designed before a single patient is enrolled. As the data is collected and the systems are built, there will likely be an iterative loop through some of these steps. The first iteration through the thought process captures intent. To prompt the ethical reflection that is integral for the documentation process, answering an initial set of questions should take place before any product or feature is built. The next iteration through the thought process captures reality and forces consideration of real-world constraints. While certain detailed sections in the datasets and system phases may not be possible to answer before the datasets are collected or the systems are built, documentation must be built into the entire ML lifecycle from start to finish and cannot simply be added at the end. Future versions of ABOUT ML will aim to include a section with details on how to implement a documentation process.