Background
Background
Importance of Data Enrichment Workers and Pathways to Improve Working Conditions
Importance of Data Enrichment Workers and Pathways to Improve Working Conditions
Data enrichment workers are central to AI development and deserve fair working conditions. Increasing transparency around the AI industry’s data enrichment practices and developing guidance for how to adopt more responsible practices has the potential to improve these conditions.
Though AI development relies on large, enriched datasets, there is still limited importance placed on how those datasets are constructed.Geiger, R. Stuart, et al. “Garbage in, garbage out? Do machine learning application papers in social computing report where human-labeled training data comes from?.” Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency. 2020 As AI continues to be deployed in increasingly sensitive contexts, increasing transparency around how the underlying datasets are created is a critical step toward closing the accountability gap in the AI industry.Denton, Emily, et al. “On the genealogy of machine learning datasets: A critical history of ImageNet.” Big Data & Society 8.2 (2021): 20539517211035955.Hutchinson, Ben, et al. “Towards accountability for machine learning datasets: Practices from software engineering and infrastructure.” Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. 2021 Examining the conditions under which the datasets that enable AI models are created is important not only to ensure the efficacy and fidelity of the models, but to ensure that the data enrichment workers who make these datasets legible to algorithmic models are treated well.
Particularly concerning are the precarious conditions data enrichment workers continue to face, despite their critical role in building the datasets that enable AI models. As the demand for this labor continues to grow, it is important to acknowledge that these workers lack formal protections and there is limited guidance for how AI companies should be interacting with these workers. The relative novelty of the demand for this type of labor poses unique challenges for companies seeking to institute ethical, worker-oriented practices.
Changing how the field treats data enrichment workers requires shifting the industry’s approach to data enrichment from an ad-hoc process to one that recognizes this labor as central to AI development.
While there has been more research and coverage on the conditions facing data enrichment workers in recent years,Gray, Mary L., and Siddharth Suri. Ghost work: How to stop Silicon Valley from building a new global underclass. Eamon Dolan Books, 2019 there is still limited transparency from various organizations in the ecosystem on how they approach data enrichment. This is partly because there are not yet field-wide standards on data enrichment practices in generalGeiger, R. Stuart, et al. “Garbage in, garbage out? Do machine learning application papers in social computing report where human-labeled training data comes from?.” Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency. 2020 — let alone on the treatment of data enrichment workers. Changing how the field treats data enrichment workers requires shifting the industry’s approach to data enrichment from an ad-hoc process to one that recognizes this labor as central to AI development.
While shifting how the broader field approaches data enrichment is not a trivial task, increasing transparency regarding current practices and developing more practical guidance can move the field towards improved conditions for data enrichment workers. Greater transparency can help emphasize the central role of data enrichment workers, create the basis for a rich public dialogue of how to improve conditions for workers, and increase confidence in AI models themselves. Disseminating tested and practical guidance will help lower the barriers for AI practitioners to navigate how to adopt more ethical data enrichment practices as standard practice.
Case Study as a Method of Increasing Transparency and Sharing Actionable Guidance
Case Study as a Method of Increasing Transparency and Sharing Actionable Guidance
This case study details how one AI company adopted responsible data enrichment sourcing practices, the challenges they faced, and how they were addressed. The accompanying resources aim to make it easier for others to adopt these practices.
Following a multistakeholder workshop series that brought together experts across industry, civil society, and academia, PAI published a white paper covering how AI practitioners’ choices around data enrichment sourcing impacts workers. The paper proposed avenues for AI developers to meaningfully improve these working conditions and helped outline the goals for what the industry should strive towards. In an effort to further lower the barriers for companies to adopt these recommendations, we needed to demonstrate the feasibility of these recommendations and develop resources that would allow companies to effectively and realistically introduce these recommendations into their workflows. Motivated by this need for actionable guidance, PAI is collaborating with AI companies to implement the white paper’s recommendations and document the process of implementing them.
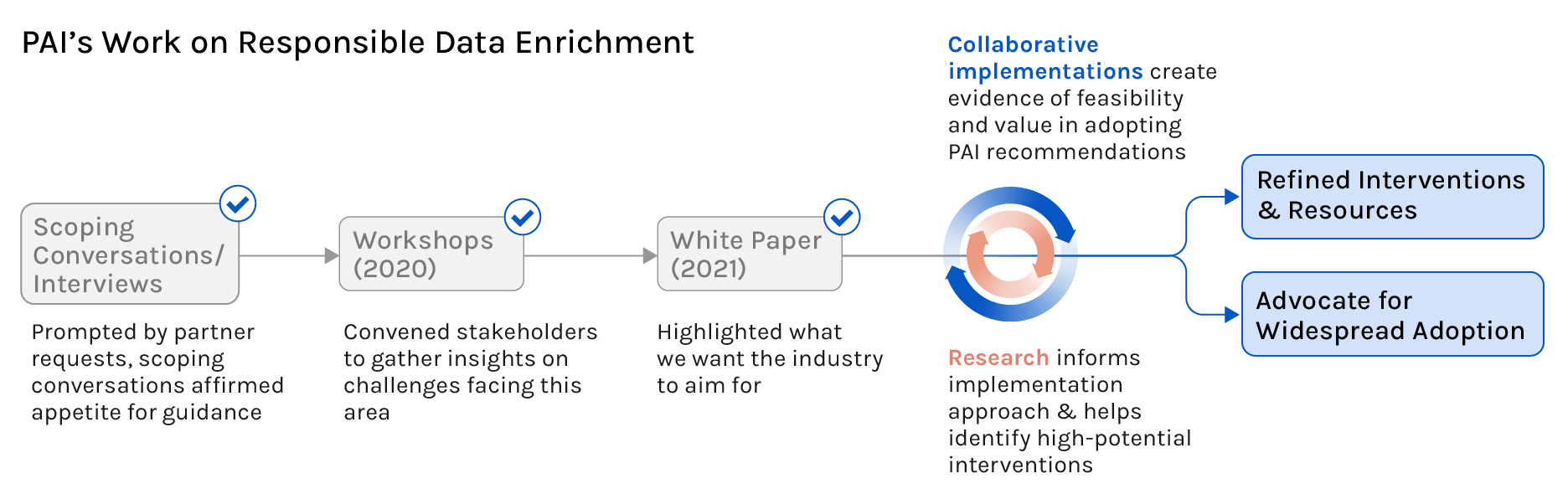
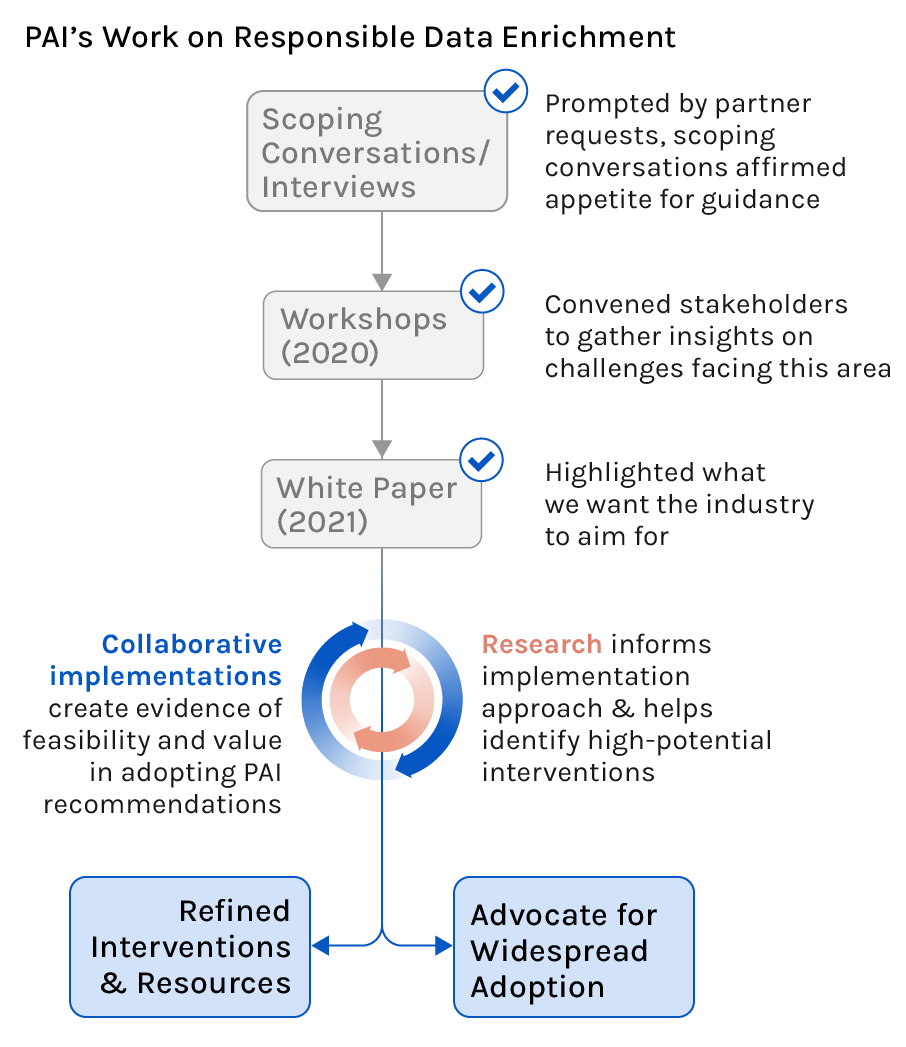
By sharing a detailed account of how one company institutionalized standard approaches to working with data enrichment workers and a refined set of resources meant to make adoption of these recommendations more feasible, we hope to help other AI companies feel better equipped to incorporate responsible data enrichment practices into their workflows.
With this transparent account we also hope to prompt a dialogue on what else companies should be doing to improve working conditions for data enrichment workers, where the limits of their influence lie, and where additional action is needed from policymakers, labor unions or data enrichment providers.
Background on DeepMind’s Motivations
Background on DeepMind’s Motivations
As more of DeepMind’s work began to involve data enrichment workers, the company recognized a need for more specific guidance and processes to uphold its commitment to building AI responsibly.
The first company we collaborated with was PAI Partner DeepMind, a British AI company with more than 1,000 employees which was founded in 2010. DeepMind is a research laboratory with an interdisciplinary team ranging from scientists and designers to engineers and ethicists. DeepMind has a Responsible Development and Innovation team with a mandate of ensuring DeepMind is upholding its commitments to responsibility by assessing the implications of their research on society, as expressed in their Operating Principles.
Given their foundation as a research-focused organization, DeepMind had an existing process to manage experiments involving human subjects or participants. This included engagement with the company’s externally chaired Human Behavioral Research Ethics Committee, which follows IRB (Institutional Review Board) protocols. This committee is tasked with reviewing projects involving research participants, meaning that their behavior is studied as part of a research project. Importantly, to fall under the jurisdiction of an IRB, research participants have to be able to freely opt in and out of studies, and payment or employment status cannot be conditional on successful completion of a task.
However, as more of DeepMind’s work began involving data enrichment workers, who receive payment for tasks performed, challenges arose with assessing these projects against IRB protocols. It became clear to the Responsible Development and Innovation team that both researchers and reviewers required more specific guidance and a dedicated review process to properly address the unique ethical challenges related to data enrichment projects. Without centralized guidance on how to set up data enrichment projects, researchers would need to invest time to independently seek out best practices and use their better judgment. A centralized set of data enrichment guidelines that incorporated considerations unique to interacting with data enrichment workers and a dedicated review process would ultimately save researchers’ time. DeepMind hypothesized that this would lead not only to a more rigorous and efficient review process but also an increase in data quality.
Additionally, DeepMind wanted a rigorous set of practices and processes to adhere to when constructing and publishing enriched datasets. In the absence of an existing set of standard practices (like IRB protocols), they turned to PAI’s white paper on responsible sourcing of data enrichment. Given PAI and DeepMind’s shared goal of improving conditions for data enrichment workers, we agreed to work together to build a set of resources that would help both DeepMind and the broader AI community to implement responsible sourcing practices.