Process and Outcomes of the DeepMind and PAI Collaboration
Process and Outcomes of the DeepMind and PAI Collaboration
To identify the resources and artifacts that would enable DeepMind employees to consistently adhere to responsible data enrichment practices, the implementation team (made up of PAI and members of DeepMind’s Responsible Development and Innovation team) began our collaboration by examining DeepMind’s existing approach and processes. Next, the implementation team developed prototypes of those resources and got feedback on them from key internal stakeholders (including researchers, engineers, program managers, lawyers, and security and privacy experts) who would either be using the resources directly or helping ensure that teams followed best practices during the data enrichment review process. The implementation team then created the internal resources, testing them with two research teams to gather further feedback and make user-informed adjustments before finalization. Once finalized, the new review process for data enrichment sourcing projects and accompanying resources were rolled out to the rest of the organization.
Changes and Resources Introduced to Support Adoption of Recommendations
Changes and Resources Introduced to Support Adoption of Recommendations
The following resources and changes were introduced to help teams source enriched data responsibly: a two-page guidelines document, an updated ethics review process, a “good instructions” checklist, a vendor comparison table, and a living wages spreadsheet.
After initial conversations with the Responsible Development and Innovation team, we intended our collaboration to result in two primary outputs: a brief document summarizing the recommendations from PAI’s white paper and an adapted ethics review process for projects involving data enrichment workers. However, the feedback collected by the implementation team from stakeholders across the organization helped identify additional resources that would help teams more effectively and consistently adopt the recommendations. (This approach to analyzing organizational needs and collecting feedback is described in Appendix A.) Below is the full list of outputs and changes resulting from this collaboration.
Two-Page Data Enrichment Sourcing Guidelines Document
Two-Page Data Enrichment Sourcing Guidelines Document
The two-page guidelines document serves as the primary reference document for all teams seeking to set up a data enrichment project and for the Human Data Review Group to know what standards to apply to any proposed data enrichment project. Based on PAI’s white paper on responsible sourcing practices, the document covers five primary guidelines and links to additional documents that might further assist teams in meeting these five guidelines. “Data Enrichment Sourcing Guidelines,” a copy of this document (with DeepMind-specific provisions removed), is available for input and use by the broader AI community on PAI’s responsible data enrichment sourcing library.
In summary, the guidelines are:
- Select an appropriate payment model and ensure all workers are paid above the local living wage.
- Design and run a pilot before launching a data enrichment project.
- Identify appropriate workers for the desired task.
- Provide verified instructions and/or training materials for workers to follow.
- Establish clear and regular communication mechanisms with workers.
In addition to these guidelines (which are explained in the Guidelines Document in more detail), it is important to mention two notable policies the company has put in place for research teams procuring enriched data. First, DeepMind has enacted a policy to prohibit mass rejections (the rejection of a large number of tasks simultaneously, often resulting in wages being withheld and workers’ ratings being lowered on platforms) without reason and always paying workers for their time unless there is clear evidence of fraud. Second, DeepMind will only use vendors in regions where workers will be paid in cash (as opposed to gift cards or vouchers).
Adapted Review Process
Adapted Review Process
DeepMind had an existing review process which any project involving human data was subject to. To ensure that study reviews remained streamlined, DeepMind adapted the existing process to include a triage stage, which determines whether projects involve research participants or data enrichment workers. All studies are required to fill out the same application forms and are assessed against the best practices guidelines, with the Responsible Development and Innovation team on hand to guide researchers through the process. Data enrichment studies are reviewed by representatives from the following DeepMind teams: Responsible Development and Innovation, Ethics Research, Legal, Security, and Data Solutions, whilst research participant studies are flagged for IRB review.
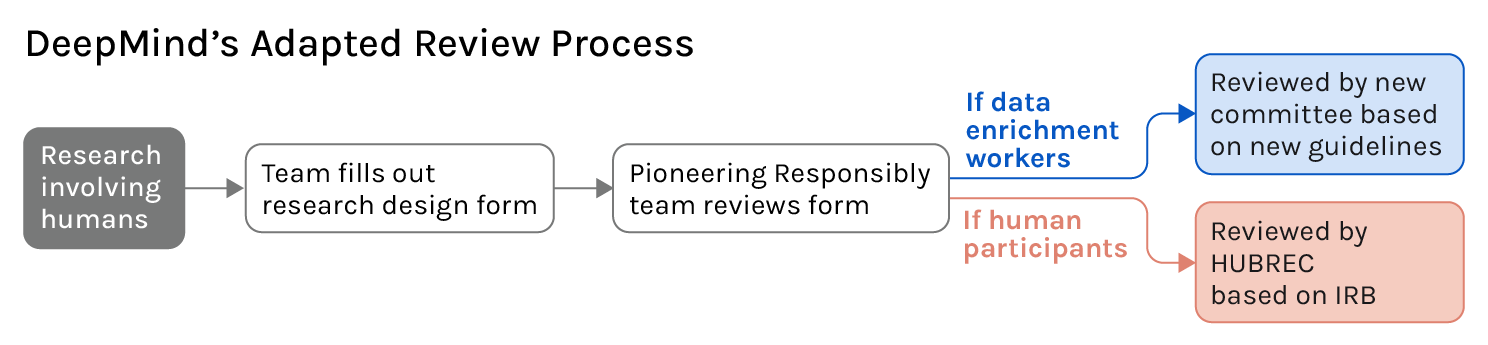
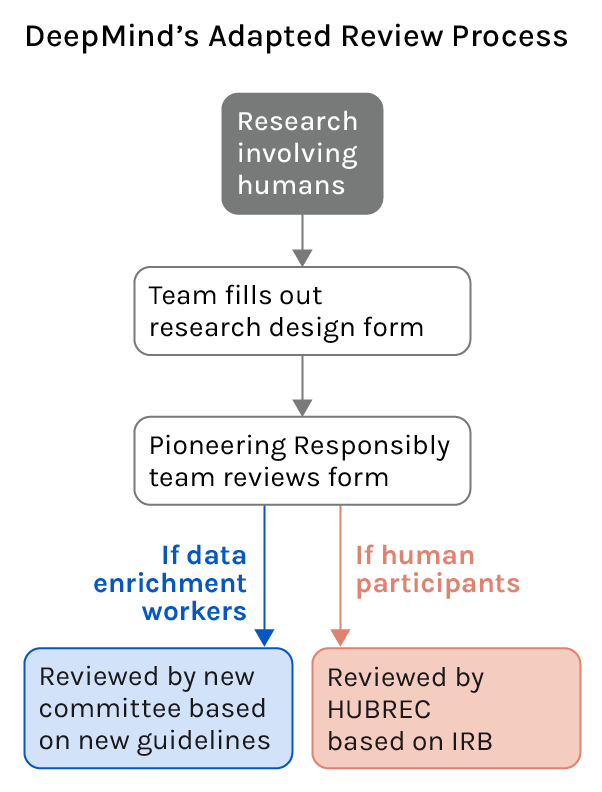
If anything on the application diverges from what is expected based on the guidelines, the team that filled out the application must provide a strong justification for requesting an exception or will be asked to make the necessary adjustments to make sure they meet the guidelines. That being said, no exceptions can be made for paying a living wage to workers and providing them with a clear recourse mechanism to get in touch with researchers in case they have questions, concerns, or technical issues.
Good Instructions Checklist
Good Instructions Checklist
The good instructions checklist is a resource detailing what should be included in a set of task instructions to make sure they are as clear as possible for workers. While this was not originally scoped as a part of the resources the implementation team would be creating, this emerged as a need during the interviews with researchers as they continued to ask what would make instructions “clear” and “good” enough for data enrichment workers to use. The first iteration of this document had a single checklist where the implementation team asked researchers to always include all criteria. However, after receiving feedback from the teams, we separated the various items into the following categories: “should always include,” “for applicable studies, include,” and “depending on the task, you may also need.”
Given the range of studies across the company, there were studies where some checklist items would not have been desirable. For instance, in many cases, including examples of common mistakes would provide workers with a concrete set of examples to avoid and thus minimize the risk of having work rejected. However, for some studies, teams might want to capture the instinct of workers and there may not be any “mistakes” for the given task. Cases like these underscore two broader challenges in the field. First, it is challenging to create guidance that is applicable across varied use cases and specific enough to actually help guide researchers. Second, cases like this highlight the blurry line (and in some cases, overlap) between workers who are building training data for AI models and human subjects whose ways of thinking about the world are being captured in training data, both of whom are contributing to building AI models. While we tried to balance between building useful tools while making the guidelines general enough to apply to different use cases organization-wide, these challenges should be kept in mind as the field attempts to develop additional guidance. “Good Instructions Checklist for Data Enrichment Projects,” PAI’s version of this checklist, can be found on PAI’s responsible data enrichment sourcing library.
Vendor and Platform Feature Comparison Table
Vendor and Platform Feature Comparison Table
This table lists different considerations for the various vendors that have been onboarded and approved by DeepMind. This table allows researchers to see any worker-oriented guidance and recommendations that are platform-specific. In speaking to researchers, it became clear that in addition to helping keep the primary guidelines document to the most important, general principles, a vendor comparison table that incorporated additional worker-centric considerations specific to a particular vendor would make it easier for researchers to find guidance that was only relevant for a given platform and help them choose the right platform for their needs. The “Data Enrichment Vendor Comparison Template,” a template for creating a similar vendor comparison table, is available as part of PAI’s responsible data enrichment sourcing library
Living Wages Spreadsheet
Living Wages Spreadsheet
This spreadsheet is a centralized resource with a list of living wages for the locales most commonly used by DeepMind researchers. The living wages listed in this spreadsheet are expected to be the minimum set by DeepMind researchers. This dynamic document will be updated as living wages change and as researchers request additional locales to be added by the Responsible Development and Innovation team. The main columns in this spreadsheet are: country, city, living wage in the workers’ local currency, living wage in the researchers’ currency, and source. For additional guidance on sources for living wages, see Appendix 1 of PAI’s “Responsible Sourcing of Data Enrichment Services” white paper. The “Local Living Wages Template,” a template for creating a similar living wages spreadsheet, is available as part of PAI’s responsible data enrichment sourcing library.
Addressing Practical Complexities That Arose While Finalizing Changes
Addressing Practical Complexities That Arose While Finalizing Changes
Putting PAI’s recommendations to the test in an applied setting allowed us to understand the complexities of adopting these guidelines in practice. Challenges to implementing PAI’s recommendations in practice included: shaping the guidelines to be usable, making the guidelines apply to diverse use cases, and setting up a payment methodology in a complicated environment.
Existing research and the multistakeholder workshop series hosted by PAI helped shape the initial recommendations for how industry can improve conditions for data enrichment workers. During this applied collaboration with an industry partner, we had the chance to see what it would take to implement those recommendations, better understand their feasibility, and identify barriers to implementing some of those recommendations. In sharing how the implementation team worked through some of the complexities that arose while implementing the recommendations, we hope to make it easier for other companies to similarly incorporate these recommendations into their data enrichment practices.
Guideline Usability
One of the primary goals of this collaboration was to make it feasible to consistently uphold responsible data enrichment practices. Critical to that goal was making sure that any proposed changes would be usable by the researchers that would be setting up data enrichment projects. The feedback collected throughout this collaboration helped the implementation team create resources that were concise enough to be usable in practice and detailed enough to serve as meaningful guidance. As a result, the primary guidelines document is relatively short at two pages to maximize readability and ease of navigation. At the same time, the document includes hyperlinks to other resources that can provide researchers with more context on how best to uphold the guidelines.
During the feedback process, researchers expressed the need for additional guidance (on topics which fell outside the scope of worker-oriented considerations) on data enrichment projects. PAI and our DeepMind collaborators weighed whether we should introduce more comprehensive guidance incorporating these additional considerations. Ultimately, the implementation team decided it was important to first align on a standardized set of responsible data enrichment guidelines as initially planned, building a shared understanding across the organization of ethical standards that needed to be met. (Since then, DeepMind has independently pursued an effort to build more comprehensive guidance.) In addition to serving as a guide for researchers, this document was also intended to serve as the primary resource for the Human Data Review Group to consult when assessing whether teams’ projects met the necessary standards.
Addressing Diverse Use Cases
Our intention was to design artifacts and processes in a way that would make it easy for researchers to consistently incorporate responsible sourcing practices into their data enrichment projects. The high level of variance in DeepMind’s data enrichment use cases made it difficult to phrase the guidance in a way that would make them applicable across all use cases. This was partially addressed by differentiating between policies that need to be followed for all studies and those that may depend on the use case. The goal was to make sure that guidelines and accompanying resources supported DeepMind researchers in making ethical decisions for their projects, even in situations the guidelines don’t explicitly cover. The review process supplements researchers’ efforts by providing an additional check on their data enrichment projects, as the review committee can provide feedback and ensure that any exceptions to the guidelines are reasonable given the context.
Our collective understanding of how to improve conditions for data enrichment workers will continue to evolve as we learn more.
Additionally, it is important to recognize that our collective understanding of how to improve conditions for data enrichment workers will continue to evolve as we learn more and new data enrichment use cases emerge (both within DeepMind and across the industry generally). At this stage, it is not possible to capture all of the worker-oriented considerations that could apply to these future use cases. This being the case, we tried to share how the guidelines would impact workers in our presentations to the teams and craft the guidelines in a way that would get researchers to think about the impact on workers more broadly when they are designing data enrichment projects.
Establishing a Payment Methodology
DeepMind has formalized a commitment to paying data enrichment workers at least a local living wage based on the best available information. However, the most specific geographic location information provided by some data enrichment platforms is at the country level. This poses a challenge because living wages can vary quite drastically within some countries. Furthermore, some studies require workers from a variety of different locales but platforms don’t always provide an easy option to set multiple wages for a single project based on the workers’ locations. These two aspects make it difficult to consistently ensure workers are being compensated fairly. While these are important follow-ups to pursue with platforms directly, DeepMind will, in the interim, still be maintaining a policy of paying workers a living wage based on their location. When setting wages, researchers are expected to use the most specific location data they have. If the exact location of the worker is not known, researchers can use the country level average for now. And, as mentioned above, a spreadsheet containing living wages for the most common locations was created to aid researchers.
Assessing Clarity of Guidelines and Rolling Out Changes Organization-Wide
Assessing Clarity of Guidelines and Rolling Out Changes Organization-Wide
To ensure the usability and fidelity of these resources and changes, we gathered feedback from research teams through group discussions, direct comment periods, interviews, and surveys.
After incorporating the feedback received from stakeholders across the organization, the implementation team wanted to roll out the guidelines, supplemental resources, and review process across DeepMind. Prior to a full roll-out, it was important to have these new artifacts tested by a few research teams to make sure the guidelines were clear and usable.
The implementation team interviewed and surveyed the initial research teams testing the new process at two different points. The first time was after the team had reviewed the guidelines and gone through the application and review process but before they had started their labeling project. The goal was to assess perceived benefits and pitfalls of the guidelines, identify areas of improvement, and evaluate if the guidelines helped change how teams approached the data enrichment project.
The second time the implementation team interviewed research teams was once their study was underway or completed. The goals here were to measure impact of implementing the guidelines, assess if the experience of implementing the guidelines differed from what they had thought when filling out the application form, assess where the guidelines/process fell short from researchers’ actual experiences, and see if researchers identified any topics where they might have needed additional guidance.
Once all the outputs had been finalized, DeepMind published all the relevant resources on an internal site accessible to all research teams and rolled this out to the broader organization through a company-wide announcement.
DeepMind will continue to collect feedback from teams going through this process and make necessary changes that will continue to make it easier for researchers to understand and follow the data enrichment guidance.