A Sociotechnical Examination of Differentially Private Federated Statistics as an Algorithmic Fairness Technique
A Sociotechnical Examination of Differentially Private Federated Statistics as an Algorithmic Fairness Technique
Differentially private federated statistics is designed to address data privacy concerns. However, as an approach, it was not explicitly developed for the context of algorithmic fairness assessments. As such, it is not inherently designed to address the other social risks associated with collecting and using demographic data, such as miscategorization or reinforcement of oppressive categories.*For example, these harms could include the group-level miscategorization of gender non-conforming individuals as male or female, reinforcing the oppressive category of the gender binary. However, this does not mean that differentially private federated statistics pose barriers to the efficacy of other strategies and approaches for responsible and ethical data collection analysis. Rather, when using differentially private federated statistics to enhance the privacy of fairness assessments, there are a number of design choices and variables to consider. It is important to note, however, that such choices may result in trade-offs, for example between privacy and analytic accuracy.*See Appendix 4 for a more detailed definition.
As previously mentioned, the ability of this technique to support a successful fairness assessment (e.g., one that overcomes the organizational and legal barriers and mitigates social risks) relies on both the design choices made by the organization and the conditions in which it is implemented. Below we detail a number of sociotechnical considerations that influence the efficacy of a fairness assessment strategy in terms of protecting individual user privacy and identification of potential algorithmic bias, particularly for socially marginalized groups.
While conducting research for this project, expert convening participants frequently discussed the importance of a full pre- and post-deployment algorithmic fairness assessment strategy, especially if the aim is to mitigate the harms experienced by socially marginalized communities. To capture the advantages presented by differentially private federated statistics, organizations must consider the way the problem is defined, the way that data is collected, who continues to be excluded and “not seen” in the data, and how the data is interpreted to guide decision-making on algorithmic bias mitigation to prevent risks and harms for individuals and communities.
General Considerations for Algorithmic Fairness Assessment Strategies
General Considerations for Algorithmic Fairness Assessment Strategies
The considerations are divided between two broad categories: 1) those related to the overall design of an algorithmic fairness assessment strategy, and 2) those related to the specific design of a differentially private federated statistics approach within that fairness assessment strategy. The first set of considerations should be understood as some of the fundamental components needed in a broader algorithmic fairness assessment strategy. Poorly determined decisions among this set of considerations may weaken the efficacy of any attempt to identify algorithmic bias, whether or not differentially private federated statistics is applied. The second set of considerations is specific to how the differentially private federated statistics is applied so that its advantages (e.g., privacy preservation) are maximized.
In general, algorithmic fairness assessments benefit from being treated as an organizational priority, as they require additional expertise, time, and organizational incentives to implement as part of the development of an algorithmic system. This is especially the case for resource-intensive approaches like differentially private federated statistics which may require additional computing capacity and team members capable of administering the overall application of differentially private federated statistics.
Algorithmic systems should be tested for bias at multiple points of development and deployment. Pre-deployment testing and assessments provide assurances that algorithmic systems have been thoroughly vetted to minimize any harmful impacts once they are in operation and interacting with the general public. Post-deployment assessments allow organizations to monitor algorithmic systems as they operate in complex human contexts. Doing so not only protects additional people from being harmed or otherwise negatively impacted by the algorithmic system but allows for developers to improve and innovate on existing algorithmic models. In order to leverage the learnings from post-deployment algorithmic fairness assessments, organizational processes must be in place to incentivize or require teams to address and resolve any identified issues.
Because algorithmic bias is sociotechnical in nature, non-technical experts such as subject matter experts in social inequality and qualitative researchers are important members of algorithmic fairness assessment teams. As we will discuss further, they are especially advantageous when defining relevant demographic groups, choosing data collection methods, considering the balance of privacy and accuracy relevant to different social groups, defining appropriate fairness or bias frameworks to apply to models, and other components of the fairness assessment process. Organizations might also work in collaboration with community groups, particularly those that advocate on behalf of marginalized communities, to support these aspects of algorithmic fairness assessment. Ultimately, effective collaboration with external experts and groups requires clear communication, establishment of trust, potential compensation (monetary or in-kind), and organizational structures to support ongoing engagement. While resource-intensive, these collaborations can lead to more robust, inclusive, and equitable fairness assessments.
- Team members involved in conducting the overarching fairness assessment, (of which differentially private federated statistics is one component) should include meaningful engagement with non-technical experts and community groups to inform their overall approach.
- This should involve setting expectations, maintaining communication, and providing compensation for those external to the organization who contribute their time and expertise.
- Organizations should provide teams with adequate time and resources to design and deploy algorithmic fairness assessments.
- Teams should obtain executive, leadership, and middle-management buy-in to ensure they receive the proper support to effectively address any bias identified.
Defining Fairness
Before beginning any type of fairness assessment (pre- or post-deployment), an organization should work towards aligning social and statistical definitions of fairness they are employing for that specific assessment. As noted by many social scientists and sociotechnical experts, fairness is an “essentially contested concept,” meaning it has “multiple context-dependent, and sometimes even conflicting, theoretical understandings.” To further complicate the definition and assessment of fairness and bias, there are many ways to translate understandings of fairness or bias into a set of statistical measurements. For example, “disparate impact” is one interpretation of bias used in legal, and increasingly in algorithmic, contexts. It is defined as a situation which appears neutral (e.g., everyone has the same odds or outcomes), but one group of people (usually of a protected class or characteristic) is adversely affected or implicated. A common measurement of disparate impact is the “80% rule,”*The 80% rule defines fairness as when a selection rate for a protected group is more than 80% with respect to the group with the highest selection rate. Note that in the US, the 80% rule is the agreed upon tolerance for disparate impact, a legal definition that governs practices in employment, housing, and other other personnel decisions. which sets a quantified threshold for discriminatory or biased outcomes. Other frequently used statistical approaches to fairness include predictive parity*Predictive parity defines fairness as when a model achieves equivalency in precision rates across subgroups. For example, a model that predicts college acceptance would satisfy predictive parity for nationality if its precision rate is the same for Canadians and Argentineans. and demographic parity*Demographic parity defines fairness as when results of a model’s classification are not dependent on a given sensitive attribute. For example, demographic parity is achieved if the percentage of Argentineans admitted is the same as the percentage of Canadians admitted, regardless of whether one group is more “qualified” than the other. (also known as statistical parity) when assessing systems for disparate impact. These technical definitions attempt to collapse social definitions of unfairness into mathematical formulas in very specific ways and have varying benefits and challenges depending on the context of the application.
Given the many ways fairness (or bias) can be defined and interpreted mathematically, it is important for organizations to both 1) apply interpretations and measurements of fairness that align with their overall values as an organization; and 2) share and discuss how fairness is being defined, both technically and socially, with the public (e.g., other researchers, policymakers, their users). It may not be possible (or worthwhile) to assess for all interpretations of fairness, so maintaining transparency about which notion of fairness is being pursued — and why — can help teams and organizations navigate discussions and criticisms related to their algorithmic fairness assessment strategies.
For example, an organization using the 80% rule or predictive parity should not claim that they are attempting to ensure fairness for all users, as these approaches do not ensure that all users will be treated equally — or experience similar outcomes — across groups, only that it will perform fairly for a majority of users. It is possible for organizations to apply many different measures of fairness in order to triangulate towards a broader interpretation of fairness. For example, an organization may rely on the 80% rule as a starting point for their fairness assessment, helping them to flag performance areas that require more granular analysis.
Who gets to define fairness for algorithmic fairness assessment strategies is also important to consider. There is increasing interest in engaging outside experts, members of adversely affected communities, broad user bases, and the general public as part of the development process. Algorithmic bias can have severe impacts on an organization’s reputation, so engaging those who will be impacted by the end product, including in the defining of “fairness,” is one proposed way of grappling with algorithmic bias, expanding public participation while building better products and systems enjoyed by users. Again, given the complexity of defining and measuring fairness, it may be appropriate to adopt a “mixed methods” approach, using both survey and qualitative methods like community-based interviews or focus groups. Being able to respond to these expectations with clear communication about what type of “fairness” the organization is trying to achieve through a fairness assessment will go far in building trust and mitigating miscommunication and harm.
- Organizations should seek alignment between technical (e.g., statistical) and non-technical (e.g., sociological) definitions of fairness.*
- Organizations should seek alignment between developer and user or public understanding and measurement of fairness.
- Organizations should practice transparency when it comes to how they define fairness.
Defining Relevant Demographic Categories
Just as fairness is an “essentially contested concept,” demographic categories are contested and context-specific. Which characteristics are measured (e.g., gender versus sex or race versus ethnicity) and the categories that are provided (e.g., male/female, cisgender woman/transwoman/gender non-binary, or female/male/two-spirit) change across different assessment situations based on such factors as what the algorithmic system does and where it is deployed.
For any algorithmic bias assessment, it is critical that the salient demographic categories are identified and appropriately defined for the analysis. This comes down to understanding which demographic categories are salient axes of bias for the context in which their product or system is operating in. In terms of defining demographic categories, some organizations may look to existing government taxonomies (for example, in a US context, the racial and ethnic categories provided in the US census may be viewed as a starting point to select salient social identity categories). However, given the known limitations of government-defined taxonomies, it is also important to conduct research to identify alternative categories and/or redefine categories to map against how they are understood and used in specific socio-political contexts.
Much like tapping into expertise outside the development team to define “fairness,” socio-political experts, users, and members of the general public can help refine the selection of appropriate demographic categories to assess algorithmic fairness. The categories of data used to measure or assess possible bias is a particularly sensitive (and contested) area of concern for many members of marginalized social groups, as the way individuals are measured may generate other harm to these marginalized groups. These harms can include miscategorization (when an individual is misclassified despite there being a representative category that they could have been classified under) or misrepresentation (when categories used do not adequately represent the individual as they self-identify). Not only can miscategorization or misrepresentation lead to psychological and emotional harm via feelings of invalidation and rejection, but entire groups of individuals would be rendered invisible within the data because they are effectively not being counted. This is particularly of concern, as important decisions are often made based on statistical analyses of populations, such as political representation, allocation of social services, and functionality of products and features.
- Organizations should allocate the necessary resources to conduct original research on appropriate measurements and metrics for the fairness assessment process.
- In order to yield a more inclusive fairness assessment process, this may include exploring what demographic categories are relevant to the deployment of their systems or features, as well as how different communities may define their own demographic attributes.
Data Collection
There are important considerations related to how an individual is able to offer the information necessary for the algorithmic fairness assessment. There are a number of methods for data collection organizations could employ, each with their own advantages and disadvantages. For example, an individual can be directly asked to select their gender identity from a limited list to determine if an algorithmic system is behaving in a gender-biased manner. These may provide the algorithmic assessment team with a “clean” dataset ready for analysis, but individuals — especially those who feel they are not accurately being reflected in the categories offered — may choose not to volunteer their information for assessment. Generally, individuals from social groups that experience miscategorization or violence due to their minority identity may be less likely to volunteer demographic and other private information out of concern for their safety. For example, in the United States where immigrant documentation status is highly politicized and policed, researchers found that asking about citizenship status on the US census significantly increased the percent of questions skipped and made respondents less likely to report that members of their household were Latino/Hispanic. For this reason, datasets would be incomplete across individuals who are very likely to be underrepresented in other datasets (e.g., training, testing) and experiencing regular exclusion from technological advances.
Another popular method is the use of open forms which allow for individuals to self-report or self-identify without the requirement to select from predefined categories. This technique can result in incomplete or highly variable datasets requiring resource-intensive cleaning which can impact the accuracy of the fairness assessment. However, it can also provide individuals with autonomy over how they define themselves which is particularly crucial for communities whose identities have been historically excluded from formal data collection efforts.
Organizations may also rely on demographic inference methods*See Appendix 4 for a more detailed definition. to proxy for traits, such as using computer vision technology to algorithmically ascribe skin tone as a proxy for race or ethnicity. While this technique can provide organizations with robust, uniform datasets, it removes agency from individuals in their ability to self-identify and can lead to miscategorization or misrepresentation. Additionally, existing measurements have been critiqued, and in some cases abandoned, for the limitations they pose for marginalized groups. For example the Fitzpatrick scale, which is often used to classify skin tone, has received criticism for its failure to accurately capture darker skin tones. In 2022, Google implemented the Monk scale which expands on the skin tone shades first established by the Fitzpatrick scale to improve categorization accuracy, particularly for people with darker skin tones. However, even this more inclusive scale fails to prevent all instances of miscategorization or overcome the issue of self-identification.
A separate issue is one of individual user consent for the collection and use of their private data. There have been a number of well-documented cases where individual data has been taken and used for other uses, such as targeted political advertising, without the individual’s knowledge or consent.*See Appendix 4 for a more detailed definition. To maintain public trust, as well as stay in accordance with different data privacy laws, it is important that when collecting personal data, active and knowledgeable consent is received by the individual providing the data. In order to receive knowledgeable consent, it may be necessary to acquire ongoing consent, rather than consent at a single point in time to provide broad accessibility to an individual’s data. Organizations should provide individuals with the opportunity to accept or refuse the provision of their data, alongside information on how their data might be used. Accessibility, clarity, scope, frequency, and language are all important elements to consider when designing an ethical consent process. For example, for IDs in Apple Wallet, users are asked to offer the use of their data for algorithmic bias assessment at the time of onboarding but may opt out at any time. If users do opt in, data is only accessed and used for 90 days (from the time of opt-in). Convening participants noted that having simple mechanisms to opt out and having a clear data retention period are important features to maintain.
Differentially private federated statistics present an advantage for some of these data collection concerns, as it ensures that the collection, storage, analysis, and sharing of an individual’s demographic data is more likely to remain anonymous and less likely to be unknowingly taken, or reconstructed, by another party. By keeping an individual’s information on their own device, rather than storing it on a central database that might be less secure, concerns regarding data breaches and misuse of user databases may be allayed. By introducing noise to the data and only reporting out results (as opposed to raw data), individuals are more protected from having their identities de-anonymized or reconstructed, mitigating some concerns related to surveillance or targeted violence.
The additional protections offered by differentially private federated statistics can also make it possible to deviate from government-defined demographic categories, as individuals may respond in ways that are more reflective of their own perceived identities without fear of being marked by those identities publicly. For example, an individual who lives in an area that treats having sex with someone of the same gender identity as a felony crime may be more willing to accurately identify their sexual orientation if their response is not stored in a central database (that could be rendered to a government agency) and cannot be de-anonymized.
- If organizations are employing data inference techniques for demographic characteristics, organizations should provide individuals with complementary opportunities to self-identify or to check their ascribed demographics.
- Teams should account for sampling bias by doing specific outreach to communities at risk of underrepresentation.
- Organizations should ensure participants are provided with clear, accessible opportunities to accept or refuse participation with an informed understanding of the privacy protection provided to them, what their data will be used for, and for how long their data will be retained.
Design Considerations for Differentially Private Federated Statistics
Design Considerations for Differentially Private Federated Statistics
Differentially private federated statistics is an approach with many different features. How these features are defined can impact whether differentially private federated statistics can strengthen or impede an algorithmic fairness strategy. The following section reviews the different aspects of differentially private federated statistics to consider when designing a robust algorithmic bias assessment strategy.
The Differential Privacy Model
Differentially private federated statistics can be designed with either local differential privacy and central (or global) differential privacy. Each of these models imposes privacy guarantees at different levels, and therefore have implications for individual privacy and the amount of trust that an individual is required to have in the organization conducting the fairness analysis.
In a local differential privacy model (LDP), statistical noise is added to an individual’s data before it is shared from their device with the central server. As a result, no raw data is shared with the organization conducting the analysis. This LDP model (Image 1) addresses the privacy concerns held by individuals when considering whether or not to contribute their data. It removes the need for individuals to trust the organization. Alongside the LDP model, organizations also have an option to incorporate a secure aggregation protocol. This is an additional privacy guarantee that is enforced after data (with statistical noise) has been aggregated from multiple individual devices on the central (or third-party) server to ensure that aggregate data will not be released unless the aggregate privacy guarantee is achieved.
In contrast, a central differential privacy (CDP) model adds statistical noise at the aggregate level once received by the central server. In this model, the central aggregator has access to an individual’s raw data before adding noise to achieve the differential privacy guarantee (Image 2). The disadvantage to this model is that it requires individuals to have more trust in the organization to protect their privacy, and therefore can negatively impact an individual’s willingness to contribute their data, leaving the organization with a less comprehensive data pool for their analysis.
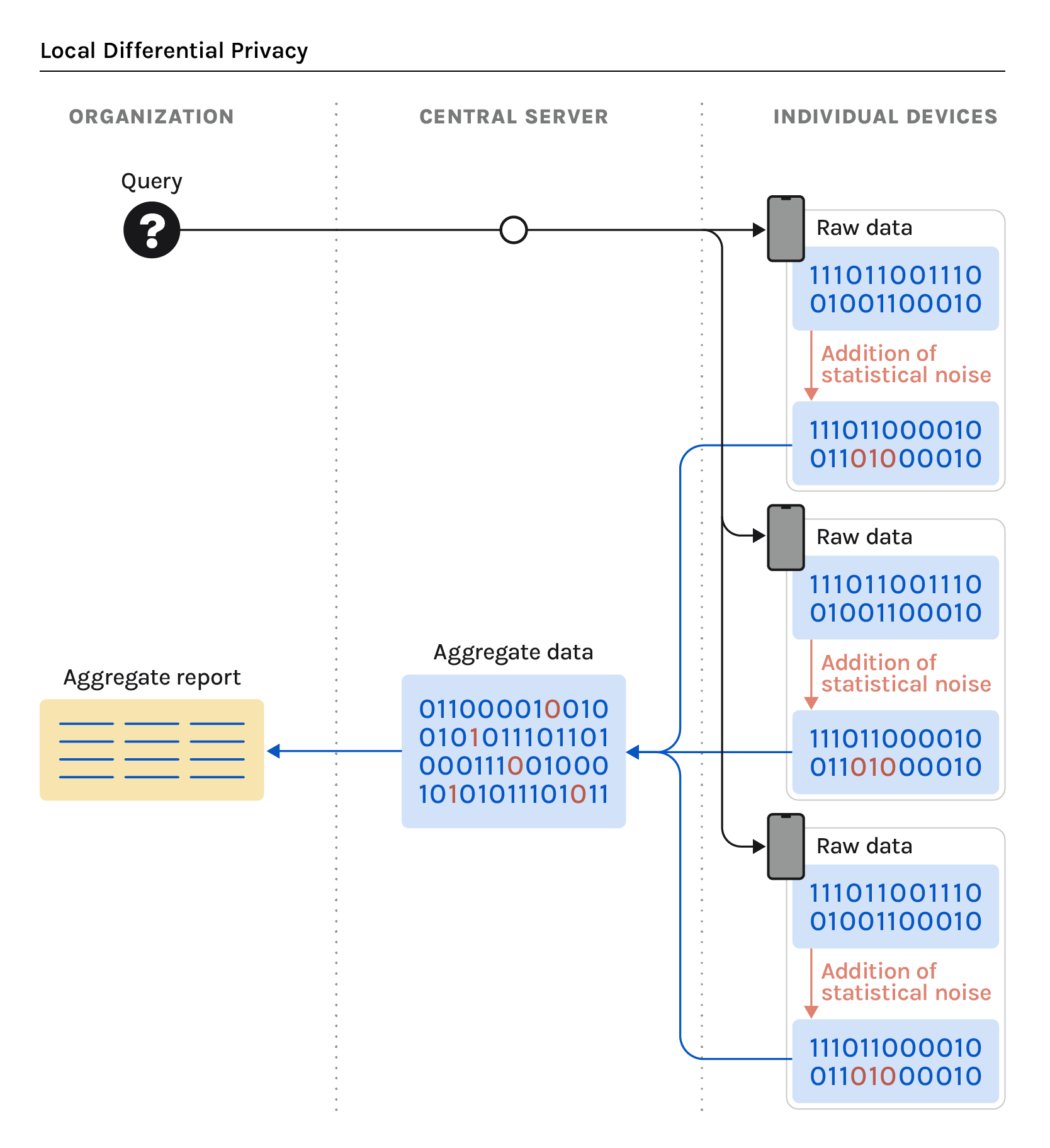
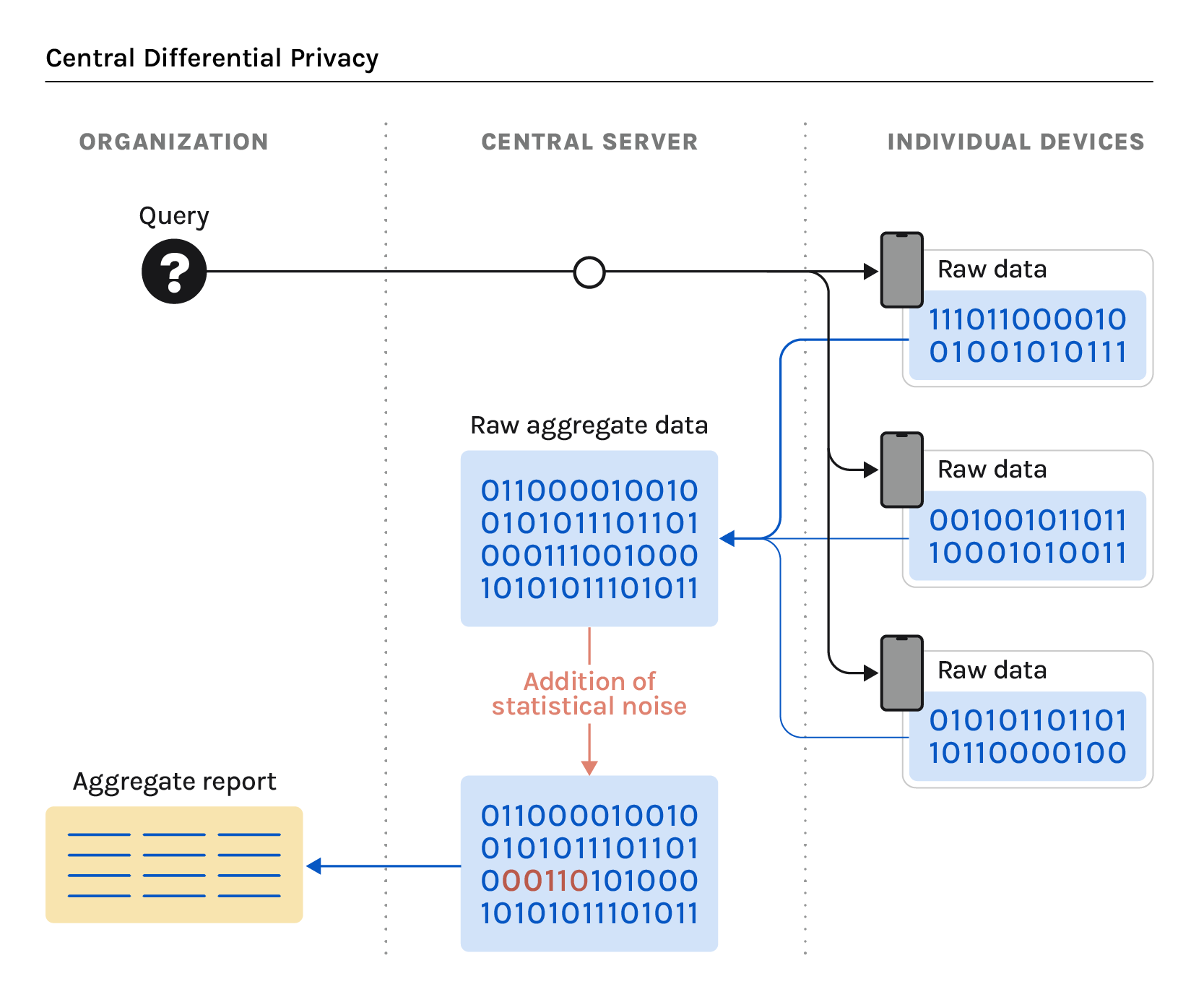
- Organizations should use local differential privacy (LDP) with secure aggregation to guarantee the highest amount of privacy protection for individuals who share their data.
- Organizations should consider incorporating a secure aggregation protocol alongside LDP to bolster privacy once data is received by the central server.
The Privacy Budget
The privacy budget, or epsilon, is a commonly accepted metric of privacy loss. The epsilon value can be seen as a spectrum, with absolute data privacy on one end and absolute data accuracy on the other: the smaller the epsilon value, the greater the privacy guarantee is for individuals, and the less utility (or accuracy) the aggregated data has. An epsilon value of 0 or 1 is considered highly private as, while a value between 2 and 10 is considered as providing some privacy, whereas a value above 10 is considered to provide little to no privacy since very little noise will be added to the original data to prevent an adversary from recognizing that a revealing output has occurred. An epsilon value can be set at the local or aggregate level under differentially private federated statistics.
When designed with strong privacy guarantees, differentially private federated statistics has the ability to ensure an individual’s sensitive data remains private and their identity remains unidentifiable in aggregate. However, while a smaller epsilon value will yield greater privacy, data analysis outputs will be less accurate (relative to the same analysis conducted with a higher epsilon value). In some instances, it may be necessary to set a higher epsilon value as more accurate data analysis is needed (e.g., analyses of groups with lower population sizes).
It is important to note that the application of differentially private federated statistics is not in and of itself a privacy guarantee: a deployment of differential privacy is only as private as the choice of epsilon. For example, organizations using differential privacy may overstate the extent of data privacy they are providing if they use a high epsilon value. By using differentially private federated statistics with a small(er) epsilon value, organizations can neutralize linkage attacks, or the ability to identify an individual using data from multiple datasets to establish a link and reveal their identity.
As noted earlier, enforcing a small epsilon — and therefore a higher degree of privacy — does pose tradeoffs for accuracy (i.e., the ability for an individual to be accounted for in a fairness assessment), particularly for demographic groups that make up statistical minorities in datasets as is often the case for marginalized communities. A smaller epsilon can render statistical minority groups invisible during analysis. This could lead to inaccurate, ineffective, or even harmful fairness assessments if small populations continue to be excluded from fairness assessments. Adding to the complexity, a larger epsilon reduces privacy guarantees which can be particularly harmful for marginalized communities who are already at higher risk of surveillance.
There is no universal balance standard for setting the epsilon. This decision depends on multiple factors including the risks to individuals and communities associated with data collection, levels of desired privacy, organizational needs, operational definition of fairness and other context specific to the fairness assessment. In some instances, it may be necessary — and even actively supported by the population of users — to set a higher epsilon value so assessment of their small group population may be more accurate and potentially subject to remediation if bias is identified.
- Teams should choose the epsilon and other privacy parameters with the needs of those most at risk of algorithmic harm as the priority for analysis and investigation.
- Focusing attention on the study of those most at risk, even when they make up a statistical minority, can generate benefits for all users.
Queries
Queries refer to pre-defined and approved functions (i.e. inquiries) that can be applied to raw data on devices resulting in an aggregate report. Choosing the correct query parameters is crucial to designing an effective fairness assessment process as the queries determine what instances of bias are or are not visible to the data analysts. For example, in assessing the functionality of a computer vision algorithm for any potential bias, a relevant query may be related to performance across gender groups for a racially diverse population given known issues of computer vision algorithms and intersectional gender bias. The chosen definition of fairness can help organizations in defining query parameters. Participatory methods, such as the inclusion of impacted communities and interdisciplinary experts, may also be employed to help identify the initial set of queries to be used to explore algorithmic bias.
When designing queries, organizations might consider factors such as the query frequency, amount permitted, and content. Within the differentially private federated statistics model, data analysts can deploy queries adaptively and tailor their queries based on previously observed responses. This poses some necessary considerations for how queries are determined and overseen. It is possible that individual devices could be “mined” excessively by deploying an endless number of queries. Adaptive queries could also make it possible to trace data points to specific devices by tailoring the questions in an increasingly more specific way to discern the device (and therefore the user and the user’s data) from another.
The practice of data minimization ensures organizations only collect the data necessary to accomplish a given task. This can be achieved through a thoughtful query design and approval process in which only necessary information is retrieved from individual’s devices and aggregated in reports. Additionally, with the appropriate restrictions and monitoring in place, it is possible to employ differentially private federated statistics to minimize the risk of, for example, re-identification using the individual data that is collected and used. For example, the differential privacy constraint can be applied to sets of queries. Instead of saying “every query must satisfy X privacy constraint,” the rule can state “the set of all queries asked this month must satisfy X privacy constraint.”*“Privacy constraint” refers to the set of rules (which assign privacy levels) to the dataset being analyzed.
Combined with retention limits, this can help effectively limit privacy loss. This can also help organizations stay in compliance with data regulation standards such as GDPR, CCPA, and HIPPA. Data minimization also helps to mitigate social harms stemming from broad data collection, such as increased surveillance and data misuse or use beyond informed consent.
Ultimately, it is important for organizations to balance varying constraints such as the need for data minimization as well as the need to obtain adequate levels of responses to conduct a robust fairness assessment.
- Teams should ensure query parameters align with the definition of fairness.
- Teams should work with interdisciplinary experts and/or community groups in designing query parameters.
- Teams should balance data minimization with the need for robust fairness assessment depending on specific context.
Data Retention
Data retention, which refers to the length of time individual data can be accessed via a query or used in aggregate before being destroyed, is an important consideration due to real and perceived threats of data breaches, potential re-identification, and being repeatedly queried. Differentially private federated statistics on its own does not prohibit the long-term storage of data, whether on the device or in a central server. This is a determination an algorithmic assessment team or the organization must establish for itself. However, this is not a straightforward choice, especially when considering the needs of marginalized communities with small populations.
A short data retention period (e.g., 30 days), for example, protects an individual from being queried many times, but small groups may be underrepresented in the overall data population at any given time. For example, if there are only 20 people out of 500 who identify as a member of a small religious sect, all 20 people would need to consent to their data usage within the same period of time in order to exceed the privacy budget threshold to be accurately analyzed as a group.
A long data retention period (e.g., two years), on the other hand, may subject an individual device to participating in many assessments, perhaps exceeding the expectations of the individual who consented to use of their data. Such a situation would also make it more likely an individual device could be re-identified if it appears across many query reports.
- Organizations should institute a data retention period to ensure individual data is not perpetually used or accessible.
- Organizations should think carefully about how the data retention period will impact their ability to identify bias when users are able to contribute their data across a long time period, particularly for statistical minorities who may not all contribute their data at once.