
Responsible Sourcing of Data Enrichment Services
As AI becomes increasingly pervasive, there has been growing and warranted concern over the effects of this technology on society. To fully understand these effects, however, one must closely examine the AI development process itself, which impacts society both directly and through the models it creates. This white paper, “Responsible Sourcing of Data Enrichment Services,” addresses an often overlooked aspect of the development process and what AI practitioners can do to help improve it: the working conditions of data enrichment professionals, without whom the value being generated by AI would be impossible. This paper’s recommendations will be an integral part of the shared prosperity targets being developed by Partnership on AI (PAI) as outlined in the AI and Shared Prosperity Initiative’s Agenda.
High-precision AI models are dependent on clean and labeled datasets. While obtaining and enriching data so it can be used to train models is sometimes perceived as a simple means to an end, this process is highly labor-intensive and often requires data enrichment workers to review, classify, and otherwise manage massive amounts of data. Despite the foundational role played by these data enrichment professionals, a growing body of research reveals the precarious working conditions these workers face. This may be the result of efforts to hide AI’s dependence on this large labor force when celebrating the efficiency gains of technology. Out of sight is also out of mind, which can have deleterious consequences for those being ignored.
Data Enrichment Choices Impact Worker Well-being
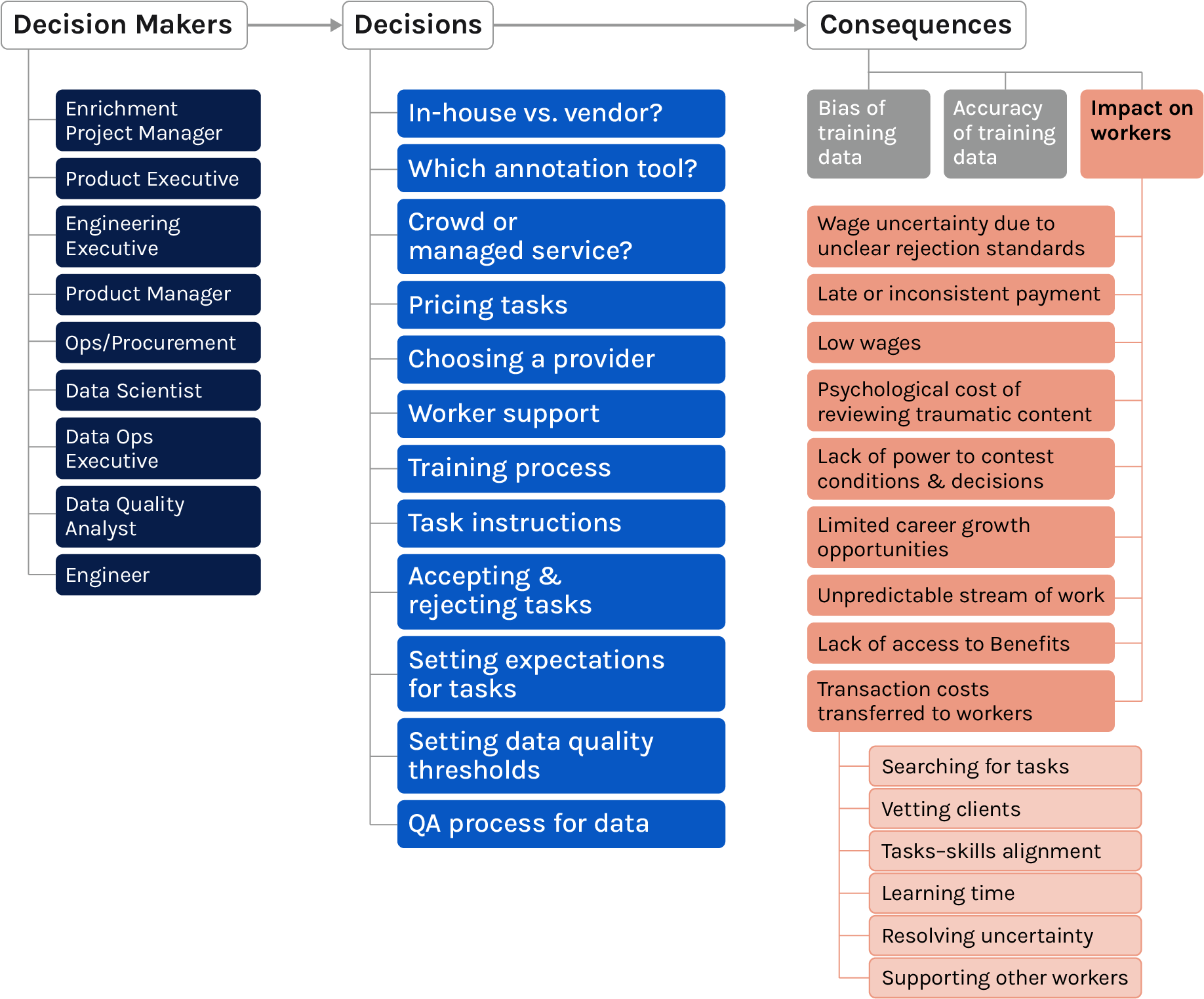
There is, however, an opportunity to make a difference. The decisions AI developers make while procuring enriched data have a meaningful impact on the working conditions of data enrichment professionals. This paper focuses on how these sourcing decisions impact workers and proposes avenues for AI developers to meaningfully improve their working conditions, outlining key worker-oriented considerations that practitioners can use as a starting point to raise conversations with internal teams and vendors. Specifically, this paper covers worker-centric considerations for AI companies making decisions in:
- selecting data enrichment providers,
- running pilots,
- designing data enrichment tasks and writing instructions,
- assigning tasks,
- defining payment terms and pricing,
- establishing a communication cadence with workers,
- conducting quality assurance,
- and offboarding workers from a project.
This paper draws heavily on insights and input gathered during semi-structured interviews with members of the AI enrichment ecosystem conducted throughout 2020 as well as during a five-part workshop series held in the fall of 2020. The workshop series brought together more than 30 professionals from different areas of the data enrichment ecosystem, including representatives from data enrichment providers, researchers and product managers at AI companies, and leaders of civil society and labor organizations. We’d like to thank all of them for their engaged participation and for valuable feedback. We’d also like to thank Elonnai Hickok for serving as the lead researcher on the project and Heather Gadonniex for her committed support and championship. Finally, this work would not be possible without the invaluable guidance, expertise, and generosity of Mary Gray.
Our intention with this paper is to aid the industry in accounting for wellbeing when making decisions about data enrichment and to set the stage for further conversations within and across AI organizations. Additional work is needed to ensure industry practices recognize, appreciate, and fairly compensate the workers conducting data enrichment. To that end, we want to use this paper as an opportunity to increase awareness amongst practitioners and launch a series of conversations. We recognize that there is a lot of variance in practices across the industry and hope to start a productive dialogue with organizations across the spectrum who are working through these questions. If you work at a company involved in building AI and want to host a conversation with your colleagues around data enrichment practices, we would love to join and help facilitate the conversation. If you are interested, please get in touch here.
To read “Responsible Sourcing of Data Enrichment Services” in full, click here.










