Fact-Checks, Info Hubs, and Shadow-Bans: A Landscape Review of Misinformation Interventions
Fact-Checks, Info Hubs, and Shadow-Bans: A Landscape Review of Misinformation Interventions


![$hero_image['alt']](https://partnershiponai.org/wp-content/uploads/2021/06/fact-checks-pattern-1800x945_big-1.png)
Big Tech CEOs have become a regular sight on Capitol Hill, called in time and time again to testify before Congress about their misinformation practices and policies. These debates often revolve around what’s been called the “false take-down/leave-up binary,” where the central question is whether platforms should allow misleading (however that’s defined) content on their platforms or not. A quick scroll through platform policies, however, will reveal a variety of intervention tactics beyond simple removal, including labeling, downranking, and information panels. When this range of approaches to misinformation is considered, far more fundamental questions arise: When should each of these approaches be used, why, and who gets to decide?
To date, there has been no public resource to understand and interrogate the landscape of options that might be used by platforms to act on misinformation. At the Partnership on AI (PAI), we have heard from our Partner community across civil society, academia, and industry that one obstacle to understanding what is and isn’t working is the difficulty of comparing what platforms are doing in the first place. This blog post is presented as a resource for doing just that. Building on our previous research on labeling manipulated and AI-generated media, we now turn our attention to identifiable patterns in the variety of tactics, or “interventions,” used to classify and act on information credibility across platforms. This can then provide a broader view of the intervention landscape and help us assess what’s working.
In this post, we will look at several interventions: labeling, downranking, removal, and other external approaches. Within these interventions, we will look at patterns in what type of content they’re applied to and where the information for the intervention is coming from. Finally, we will turn to platform policies and transparency reports to understand what information is available about the impact of these interventions and the motivations behind them.
This post is intended as a first step, providing common language and reference points for the intervention options that have been used to address false and misleading information. Given the breadth of platforms and examples, we recognize that our references are far from comprehensive, and not all fields are complete. With that in mind, we invite readers to explore and add to our public database with additional resources to include. As a result of our collective work, platforms and policymakers can learn from these themes to design more informed and valuable interventions in the future and better debate what it means for an intervention to be valuable in the first place.
Our process for defining interventions
It seems like every other day a platform announces a new design to fight misinformation, so how did we decide on which interventions to categorize? We started by comparing a non-comprehensive subset of several dozen interventions (and counting) on top social media and messaging platforms for an initial categorization of intervention patterns, based on usage statistics. We also included some data about other platforms with lower usage statistics, including Twitter, due to its prominent interventions and interest amongst the Partnership on AI Partners in our AI and Media Integrity Program.
We included any intervention we found that was related to improving the overall credibility of information on a platform. That means the focus of interventions is not always limited to “misinformation” (the inadvertent sharing of false information) but also disinformation (the deliberate creation and sharing of information known to be false), as well as more general approaches that aim to amplify credible information. Note that public documentation of these interventions varies widely, and in some cases may be outdated or incomplete. In general, we based our intervention findings on conversations with PAI Partners, available press releases, platform product blogs, and external press coverage. If you see something to add or correct, let us know in the submission form for our intervention database!
Classifying interventions
In order to organize the patterns across interventions, we classified them according to three characteristics: 1) type of intervention, 2) element being targeted, and 3) the source of information for the intervention. These characteristics emerged as we noted the key differences between each intervention. Apart from the surface design features of the intervention, we realized it was key to address what aspect of a platform the design is applied to (for example, labeling on individual posts vs. accounts) as well as where the information was coming from, or the source. We’ll walk through these high-level patterns, summarized in the table below:
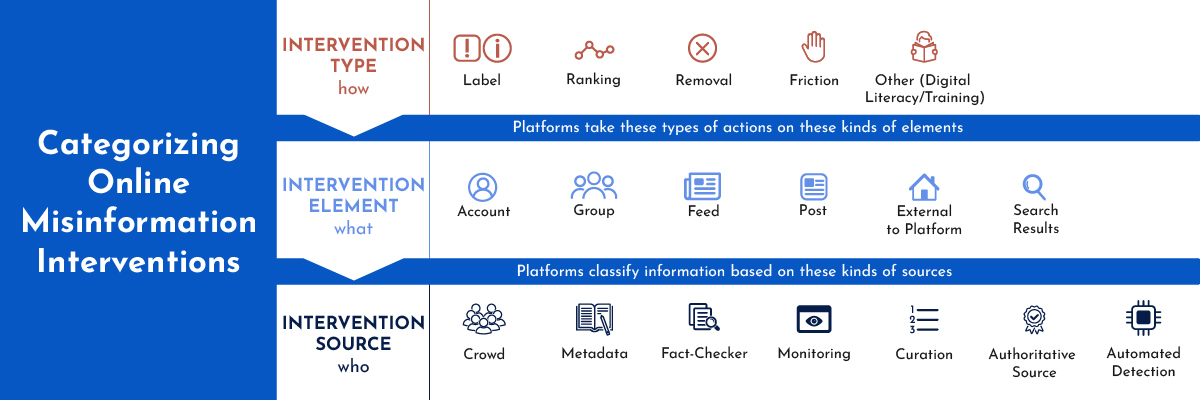
1. What is the type of intervention?
There are many ways platforms might intervene on posts that they classify as false or misleading (more on the complexities of such classifications in part three). You might already be familiar with some tactics, such as fact-checking labels or the removal of posts and accounts. Others, like downranking posts to make them appear less often in social media feeds, you might not think of, or even be aware of. We refer to these various approaches as “interventions,” or “intervention types,” as the high-level types of approaches employed by platforms.
Note that the visual and interaction design of interventions can vary widely, even for interventions of similar types (e.g. veracity labels on Facebook compared to those on Twitter feature different terminology, colors, shapes, and positions). In this post we focus on general approaches, rather than comparing specific design choices within types.
Labels
Labels are one of the more noticeable and varied types of interventions, especially as platforms like Facebook have ramped up to label millions of posts related to COVID-19 since 2020. We define labels as any kind of partial or full overlay on a piece of content that is applied by platforms to communicate information credibility to users.

However, labels are far from alike in their design: in particular, we differentiate between credibility labels and contextual labels. Credibility labels provide explicit information about credibility, including factual corrections (for example, a “false” label, also known as “veracity label” in a review by Morrow and colleagues in 2021). Contextual labels, on the other hand, simply provide more related information without making any explicit claim or judgement about the credibility of the content being labeled (for example, TikTok detects videos with words related to COVID-19 vaccines and applies a generic informational banner to “Learn more about COVID-19 vaccines”).
Beyond this, label designs can vary in other crucial ways, such as the extent to which they create friction for a user or cover a piece of content. Labels may be a small tag added alongside content or may make it more difficult to open the content. Each choice may have profound implications for how any given user will react to that content. For a more thorough discussion of the tradeoffs in design choices around labeling posts, you can check out our 12 Principles for Labeling Manipulated Media.
Ranking
Platforms with user-generated content, such as Facebook and TikTok, use various signals to rank what and how content appears to users. The same ranking infrastructure used to enhance user engagement has also been used to prioritize content based on credibility signals. For example, Facebook has used a “news ecosystem quality” (NEQ) score to uprank certain news sources over others. Conversely, downranking can reduce the number of times content appears in other users’ social media feeds, often algorithmically. For example, Facebook downranks “exaggerated or sensational health claims, as well as those trying to sell products or services based on health-related claims.” At the extreme end of this spectrum, content may even be downranked to 0, or “no ranking,” meaning content will not be taken off of a platform, but it will not be algorithmically delivered to other users in their feeds. The ranking scores of any given content remains an opaque process across platforms, thus it is hard to point to examples that had a low ranking (that is, were “downranked”) vs. those with no ranking.
Removal
Removal is perhaps the most self-explanatory—and often most controversial—approach. We define removal as the temporary or permanent removal of any type of content on a platform. For example, Facebook, YouTube, and others removed all detected instances of “Plandemic,” a COVID-19 conspiracy theory video, from their platforms in May 2020.
Other (e.g. digital literacy campaigns)
Though labeling, downranking, and removal are the most prevalent types of approaches, platforms also employ other methods related to promoting digital literacy and reducing conflict in relationships. We’ll discuss more specific examples in the next section.
2. What element is being targeted?
While a lot of attention has been given to platform actions on individual posts, interventions act on a lot different levels. To understand the intervention landscape, it’s worth knowing and considering what element on a platform is being targeted. In assessing interventions, we found that different approaches act on different scopes of content, including posts, accounts, across feeds, and external efforts.
Posts
Post-level interventions are arguably the most visible and salient to users, as platforms indicate that specific posts of interest have been flagged and removed. This sometimes seems to trigger a “Streisand effect” in which the flagged posts receive additional attention for having been flagged. (This is especially true when the poster is a prominent public figure, such as former President Donald Trump.) In addition to credibility labels with explicit corrections such as Facebook and Instagram “false information” ratings, interventions on posts can also include contextual labels that simply provide more information, such as TikTok’s labels on posts tagged with vaccine information encouraging users to “Learn more about the COVID-19 vaccine.”
Additionally, some post-level interventions like downranking are by definition less visible, as posts classified to be downranked, for example on Facebook due to exaggerated health claims, are distributed less on social media feeds. In these cases, users may only suspect that an intervention has taken place without being able to confirm this. Finally, post-level interventions also include sharing or engagement restrictions, such as WhatsApp’s limits on sharing messages more than five times.
In many cases, these post-level interventions may be done in tandem with each other. For example, when Facebook adds a fact-checking label, the post is also downranked, and when Twitter labeled certain Trump tweets following the 2020 election for containing misleading information, liking and sharing was also prohibited.

Accounts and Groups
Account/group interventions target a specific user or group of users. When labeled, they are typically contextual in nature, offering identity verification according to platform-specific processes, or else surfacing relevant information about an account or group’s origin, such as the account’s country or if it is state-sponsored.
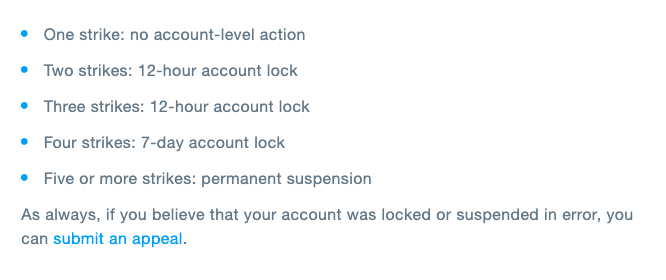
Accounts and groups are also subject to downranking and removal. Sometimes this is temporary or conditional until certain changes are made, such as the deletion of an offending post. Other times it is permanent. For example, platforms like Twitter have released guidelines detailing different account actions taken according to a five-strike system.
Feed-level
Instead of targeting individual posts or accounts, some interventions affect an entire platform ecosystem. Examples of feed-level interventions include the “shadow banning” of certain tags, keywords, or accounts across a platform, preventing search. It is not always clear what feed-level actions are taking place, leading to widespread suspicion and speculations of bias—for example the debunked idea that conservative accounts and keywords are systematically downranked and banned across platforms like Facebook for ideological reasons.
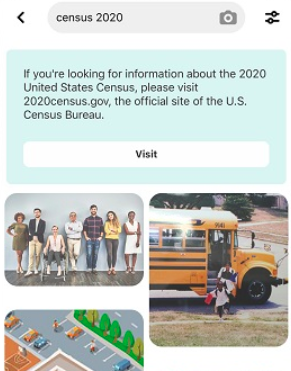
There are feed-level labels as well, such as information hubs and information panels that are displayed prominently on platforms without being attached to particular posts. The banners shown on Twitter, Facebook, Instagram ahead of the 2020 U.S. elections, which linked to election resources, are one prominent example. Other feed-level labels only appear when triggered by search. These can take the form of both credibility and contextual labels. Google, for example, highlights a fact-check if a query matches a fact-check in the ClaimReview database. And on Pinterest, merely searching for a keyword related to a misinformation-prone topic like “census” results in a banner linking to additional information.
External Efforts
Finally, in some cases, platforms don’t depend on labels, removal, or ranking, and instead aim to promote digital literacy education either using embedded digital literacy educators and fact-checkers or outside of a platform environment entirely. This tactic is particularly useful in closed messaging environments where content can’t be easily monitored for privacy reasons. For this reason, platforms like WhatsApp have announced funding for seven fact-checking organizations groups to embed themselves in groups and find other relational approaches to promote credibility. In other cases, the intervention involves direct support of partner sources identified by a platform as credible to create ads or other content to be amplified to users.
3. What are the intervention sources?
In making intervention decisions, platforms must decide what to intervene on. They currently rely on a variety of sources to both identify the need to intervene and provide what they consider authoritative information. We refer to these actors and institutions as “intervention sources” and in many ways, the quality of an intervention can only be as good or trustworthy as its source, regardless of other design factors. These intervention sources include different systems, both human and algorithmic. Below we describe sources including crowds, fact-checkers, authoritative sources, and user metadata.
Crowd
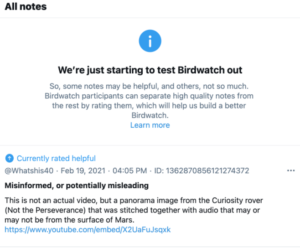
Very few crowd-based rating systems for misinformation currently exist publicly. In 2021, Twitter released Birdwatch in beta. The platform allows users to add notes with ratings about the credibility of posts. Others may then rate these notes, and the most “helpful” notes are surfaced first.
An early study from Poynter observed very low engagement with the feature, as well as evidence of politicized notes. Indeed, ensuring quality of notes and preventing organized gaming of ratings by motivated political actors remains a challenge for any crowd-based intervention at scale—a challenge that Twitter itself is attentive to.
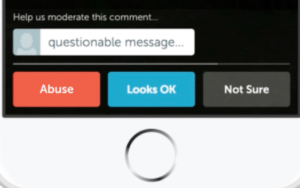
Similar tools using reporting features exist for moderating hate speech. For example, in 2016 Periscope released a feature that polled random users about whether reported messages were appropriate until a consensus was reached, at which point the offending user would be either allowed to post or be penalized. Users were shown the results of the poll. Though not explicitly about mis/disinformation, the feature offers an interesting model for random jury-based polling for use in content classification.
Fact-checkers
One of the more publicized sources of intervention information are fact-checkers. A group of fact-checkers came together following the 2016 election offering to help Facebook check the credibility of its posts. Such organizations are now approved by the IFCN (International Fact-Checking Network). These fact-checking members are contracted by platforms such as Facebook to provide ratings on posts, either according to platform-specific classifications (as with Facebook), or broader industry schemas, such as ClaimReview developed by schema.org and the Duke Reporters’ Lab (as with Google).
Facebook has described how ratings are extended in concert with multi-modal automated detection tools to flag duplicate issues across posts—though these are not always applied accurately due to the difficulties of appropriately assessing a user’s context and intent at scale.
Authoritative Sources
In some cases where technical and specialized information is involved, such as election regulations, COVID-19, and the census, platforms have followed the recommendations of relevant expert organizations.
This approach may seem to offload the responsibility of the platforms to be “arbiters of truth” by instead depending on credible institutions. In practice, however, the authority of these institutions has also proved contentious in the context of a politicized information ecosystem—for example, Facebook promotes CDC information even as many debate the agency’s changing policies.
Additional sources included curated lists of tags/accounts, internal monitoring/content moderation, other platform curation of stories, and other metadata such as the provenance of a photo. While many platforms also utilize automated detection, it is crucial to recognize that this detection is still based on prior classification by sources such as those listed above.
Where to go from here
Now that we are equipped with a basic understanding of how misinformation interventions operate, how can we tell what they are meant to do and whether they’re doing it? Here we face a deeper problem: a lack of standardized goals and metrics for interventions. Though such interventions appear to have societal goals related to harmful misinformation, they are, in many ways, still treated like any other platform feature, with limited public-facing explanations. And while many platforms regularly release public statistics, these rarely include information about specific interventions other than high-level counts of actions such as “posts removed.”
As a result, external parties have turned to novel auditing approaches. These include the use of general social monitoring tools such as CrowdTangle, opt-in browser research panels as built by The Markup, and direct questioning of platform contacts. Researchers have also asked for dynamic “Transparency APIs” to track and compare these and other changes in real time for reporting reasons, but many have yet to receive the kinds of data they need to conduct the most effective research. For a summary of current research approaches, see “New Approaches to Platform Data Research” from NetGain Partnership. The report points out that even as platforms provide total numbers and categories of information removed, they aren’t informative about “the denominator” of the information total, or what kinds of groups information is and isn’t distributed to. Because of this, there is very little structured information about the efficacy of specific interventions compared to each other. This results in researchers scraping details from product blogs, corporate Twitter threads, and technology reporting.
If these interventions are to have a positive societal impact, we need to be able to measure that impact. This might start with common language, but ultimately we’ll need more to be able to compare interventions to each other. This begins with platforms taking responsibility for reporting these effects and taking ownership of the fact that their intervention decisions have societal effects in the first place. Our prior research surfaced widespread questioning and skepticism of platform intervention processes. In light of this, such ownership and public communication is essential to building trust. That is, platforms can’t simply count on tweaking and A/B testing the color scheme and terminology of existing designs to make the deeper social impacts they appear to seek.
Going forward, we need to examine such patterns and ad hoc goals. We also need to align on what other information is needed and ongoing processes for expanding access to relevant metrics about intervention effects. This includes further analysis of how existing transparency reports are used to understand how they might be more valuable for affecting how users come into contact with content online. Platforms should embrace transparency around the specific goals, tactics, and effects of their misinformation interventions, and take responsibility for reporting on their content interventions and the impact those interventions have.
As a next step, the Partnership on AI is putting together a series of interdisciplinary workshops with our Partners with the ultimate goal of assessing which interventions are the most effective in countering and preventing misinformation—and how we define misinformation in the first place. We’re complementing this work with a survey of Americans’ attitudes towards misinformation interventions. In the meantime, our database serves as a resource to be able to directly compare and evolve interventions in order to help us build a healthier information ecosystem, together.
How to contribute to our Intervention Database
Do you have something to add that we didn’t cover here? We know our list is far from comprehensive, and we want your help to make this a valuable and up-to-date resource for the public. Let us know what we’re missing by emailing aimedia@partnershiponai.org or submitting an intervention to this form and we’ll get to it as soon as we can. Stay tuned for more updates on future versions of this database and related work.