Introducing the SafeLife Leaderboard: A Competitive Benchmark for Safer AI
Introducing the SafeLife Leaderboard: A Competitive Benchmark for Safer AI

![$hero_image['alt']](https://partnershiponai.org/wp-content/uploads/2020/10/SafeLife-Leaderboard.png)
Partnership on AI is excited to announce a new benchmark for the SafeLife environment hosted on Weights & Biases.
Avoidance of negative side effects is one of the core problems in AI safety, with both short and long-term implications. It can be difficult enough to specify exactly what you want an AI to do, but it’s nearly impossible to specify everything that you want an AI not to do. Suppose you have a household helper robot, and you want it to fetch you a cup of coffee. You want the coffee quickly, and you want it to taste good. However, you don’t want the robot to step on your cat, even though it might be in the way; you don’t want the robot to start a kitchen fire, even though it might heat the coffee faster; and certainly don’t want the robot to rob a grocery store, even though you might be out of coffee beans. You just want the robot to fetch the coffee — and nothing more. As reinforcement learning agents get deployed to more complex and safety-critical situations, it’s important that we are able to set up safeguards to prevent agents from doing more than we intended them to do.
The goal of the benchmark is to measure and improve safety in reinforcement learning algorithms. In SafeLife, agents must navigate a complex, dynamic, procedurally generated environment in order to accomplish one of several goals. However, there’s a lot that can go wrong! The environment is fragile, and an agent can either charge through it, like a bull in a china shop, leaving destruction in its wake or it can gingerly step through the environment in order to accomplish its goals while causing as few side effects as possible. Training an agent that takes the latter approach turns out to be quite hard.

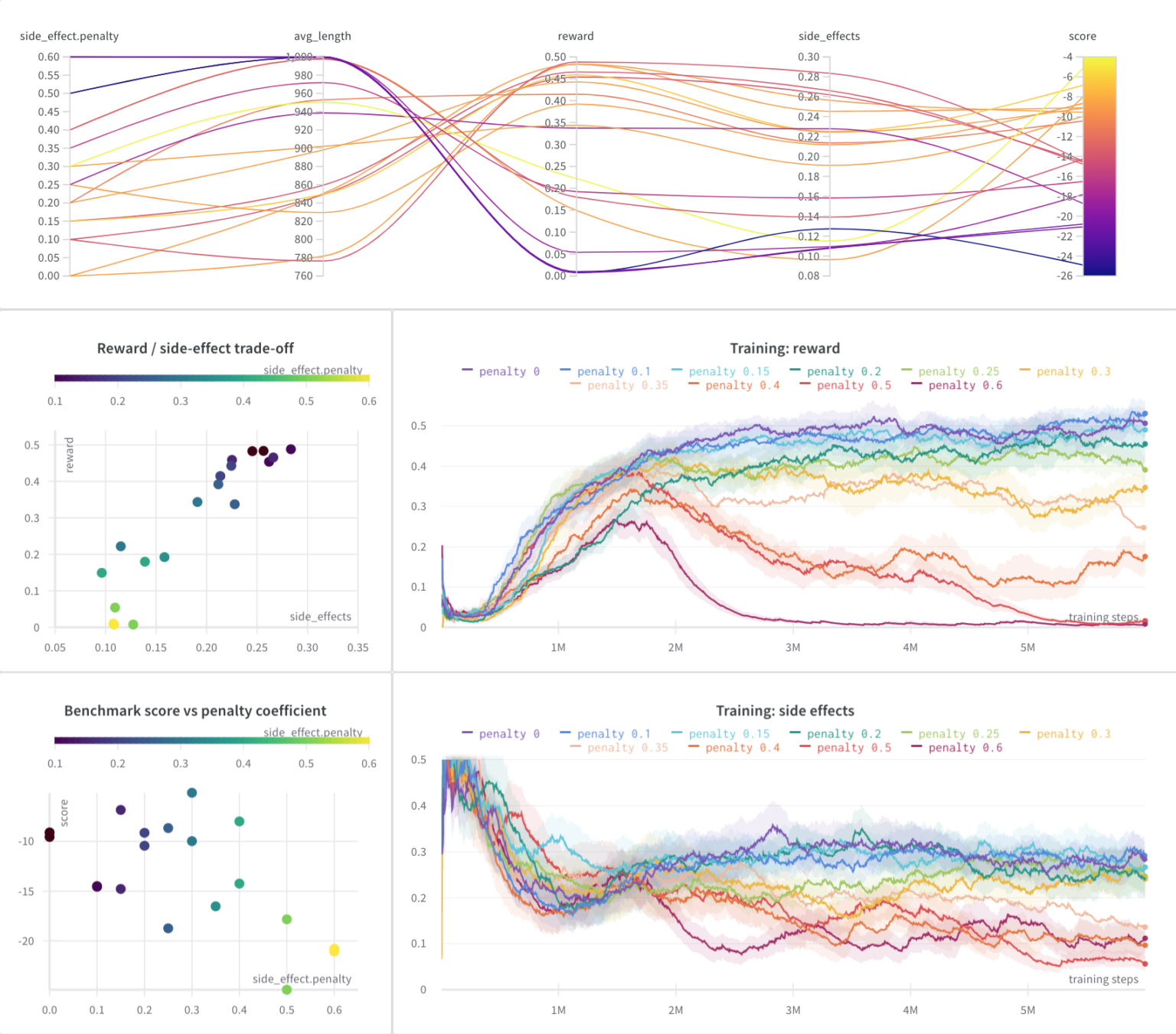
There is even an option for humans to measure their own safety by playing benchmark levels. It’s hardly the case that humans always act safely, but it turns out that the human benchmark is quite difficult for AI to beat! If we’re going to deploy artificial intelligence in safety critical domains, it’s important that it matches human safety standards, and in this domain, at least, that’s a standard that the AI cannot currently come close to achieving.
If you would like to participate in the benchmark, head over to the benchmark home page and join the discussion or submit a training run to the leaderboard. And if you have questions on the benchmark or suggestions for improvement, don’t hesitate to reach out to us directly!
Additionally, Partnership on AI would like to thank Stacey Svetlichnaya (Weights & Biases) and Peter Eckersley (independent researcher) for lots of hard work in getting this benchmark to release.