Manipulated Media Detection Requires More Than Tools: Community Insights on What’s Needed
Manipulated Media Detection Requires More Than Tools: Community Insights on What’s Needed



![$hero_image['alt']](https://partnershiponai.org/wp-content/uploads/2021/07/768145_Blog-Image_02_070920-1024x538-1.png)
The challenge of identifying manipulated media, specifically content that deceives or misleads, is rightfully an urgent consideration for technology platforms attempting to promote high quality discourse. In June, Twitter labeled one of President’s Trump’s tweets as manipulated media. This was not the first time in recent weeks that the platform added warning labels to the President’s posts, which have been previously flagged for containing misleading information. It was, however, the first time that Twitter labeled President Trump’s Tweets to highlight that the video shared in the post was manipulated. According to Twitter’s policy, the post featured a video that had been “significantly and deceptively altered or fabricated” and is likely to cause harm. Four million users had seen the post before it was labeled, highlighting the challenge of identifying and making judgments about manipulated content at the pace at which content spreads online and the scale of the Internet.
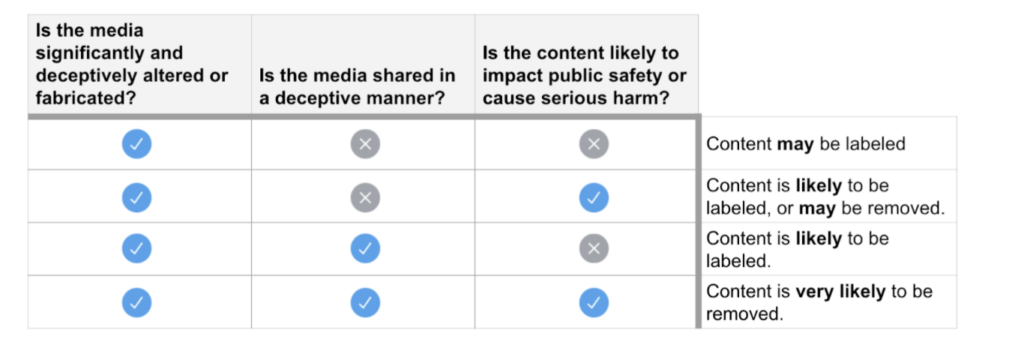
Twitter synthetic and manipulated media policy criteria
Several technology companies have turned to machine-learning based models for detecting manipulated media, both cheapfakes and more sophisticated, AI-generated synthetic media (deepfakes). However, it is not just the technology platforms alone that must gauge whether or not content has been manipulated, and even when doing so, they often rely on judgments from other actors. Journalists, fact-checkers, human rights defenders, policymakers, and others in civil society globally [1] provide important local and contextual editorial judgments about media—they consider how and why media has been manipulated and judge media’s potential impact on audiences. These actors in the media verification ecosystem should therefore be equipped with tools and training to detect manipulated media.
In order to ensure the usefulness and availability of manipulated media detection tools, the Partnership on AI (PAI) hosted a Synthetic Media Detection Tools Workshop Series in May 2020 which included around 40 representatives from journalism, fact-checking, human rights, technology, media forensics, and mis/disinformation. While we set out to explore opportunities for creating and coordinating detection tools to counter malicious manipulated media, we discovered that these tools will not be useful without investment in a number of related efforts. Bettering detection tools depends on developing more robust machine learning detection models, addressing the adversarial dynamics of detection, reaching conceptual agreements as a global community on what constitutes misleading or harmful content, addressing cheapfakes, deepfakes, and misleading context, and building media forensics capabilities outside of the large technology platforms.
Drawing on presentations and discussion at the workshop, this post suggests strategies to make manipulated media detection tools as effective as possible, while also suggesting related work areas that would build manipulated media mitigation capacity in the global verification community. We offer key considerations to make such tools as useful as possible for serving the verification community’s needs and suggest future efforts that bolster the media verification community with knowledge and capabilities to best evaluate media online.
[1] Note: We refer to this group of actors throughout as the “media verification community,” while acknowledging these actors have different, specific needs. We explain some of those needs for different groups throughout the document.
Six Questions for Manipulated Media Detection Tool Builders to Consider
The usefulness of a manipulated media detection tool depends on much more than accurate detection models. It also depends on appropriate design, deployment, and support for the tool, which means any tool must be developed in consultation with those in the media verification community. It is vital to consider how such tools fit into the workflow and decision-making processes of fact-checkers, journalists, and other media verifiers working to understand not just whether media was manipulated, but the meaning of those manipulations and the appropriate response to such knowledge.
The PAI Synthetic Media Detection Tools Workshop Series highlighted gaps between existing detection tool offerings and what media verifiers need from such tools. Participant needs informed the following key questions for detection tool builders:
1. How accurate are the machine learning models for real use cases?
High-stakes content decisions cannot rely solely on potentially inaccurate and uninterpretable technical signals. Tool builders must ensure that they are honest about the technical limitations of their detection tools, and make clear that such tools should not be used to independently come to conclusions about whether or not media has been manipulated. While potentially useful as triage tools for large platforms deciding which pieces of content warrant human review, detection models are not accurate enough to independently guide intervention decisions about specific content.
The latest results of the Deepfake Detection Challenge, a machine learning contest designed to promote development of models that detect AI-generated and manipulated videos, highlight the limitations of the current state-of-the-art in technical detection. While deepfake detection models perform well on datasets featuring content similar to their training data, they fail to generalize. The same can be said of other noble efforts by academics and technology companies like Google to create large-scale datasets for improving detection methodologies. The winning Deepfake Detection Challenge models can detect deepfakes similar to the training dataset a little over 82% of the time; however, when tested against a new dataset with different content, top model performance dropped to around 65% of fakes detected. These models incorrectly label genuine media as fake (false positives) and incorrectly label fake media as genuine (false negatives). This low accuracy is a fundamental limitation for using the output of machine learning-based tools to decide whether media has or has not been manipulated.
The media verification community needs detection tools that can successfully interpret manipulations of all types of people. Poor detection accuracy for different sub-groups—such as individuals with skin disorders, or children—can make manipulated media classifiers less useful for identifying manipulations that may cause harm to civilians. In an ideal world, detection methods would be trained and employed as appropriate for specific use cases, with dataset development and deployment informed by civil society and human rights groups. This would not only make the tools more effective, but also more fair.
One promising method for improving both the accuracy and diversity of detected manipulations is to build detection tools that use multiple models, a technique known in machine learning as an ensemble. Multiple models for detecting the same manipulation can improve accuracy because each compensates for the weaknesses of the others, while multiple models for different manipulations allow identification of a broader range of synthetic media.

Image adapted from Li, Yang, Sun, Qi, & Lyu, 2020, depicting fake videos in some of the largest deepfake detection model datasets, highlighting some of the common visual artifacts that make it difficult to train generalizable detection models.
Google Jigsaw’s detection tool, Assembler, takes this ensemble approach, using input from multiple detectors to improve accuracy and mitigate some of the problems with individual training datasets. This still leaves the issue of usefully conveying the limitations of detection models, such as what the error rate is, where the detector can be expected to be most and least accurate, and what factors determined the output on any particular media item.
Ultimately, tool builders must consider the limitations of the machine learning technologies underlying tools when deploying them and describing the capabilities of such tools. They should also strive to improve the quality of the models through collaboration and more generalizable datasets, though model improvement alone will not address detection’s broader limitations.
2. How resistant is the tool to adversarial attack?
Tool builders must recognize that if a detection tool is publicly available, it is unfortunately a question of when rather than if it will be beaten by adversaries looking to evade detection. According to an expert at our workshop, there are about two times as many academic articles published on deepfake generation as there are on deepfake detection. The adversarial, “cat-and mouse” nature of manipulated media detection may quickly render the highest quality detectors obsolete.
One expert suggested that given unlimited access to a detection tool, it would only take a day to create a novel generator that can fool it. There are motivated geopolitical actors who might well wish to do this in order to produce media to manipulate public opinion. How, then, can the media verification community work to keep up with the fast development of new manipulated media synthesis methods? Several organizations—mostly technology companies—have taken a step in the right direction by employing AI red-teams to attack state of the art detection models, in order to evaluate their adversarial robustness. But adversarial testing first needs to define the adversary.
Currently, there is no consensus view on the actual threats from malicious actors around the world, including which types of media manipulations they are likely to try to use, and which issues or events they might most want to influence. The community needs to conduct threat and adversary modeling exercises that clearly define who is being protected from what, keeping in mind that people in different regions and contexts might assess threats and adversaries differently.
3. Who gets access to the tool, and why?
Who gets access to detection tools is a question of the utmost importance. Tool builders should weigh the tradeoffs between providing a completely public detector that could be broken by adversaries, and a completely private detector that, while resistant to adversaries, does not serve the broader media verification community.
As a community, we need to think through creative solutions to uphold the advantage of detection over malicious manipulated media generation, while granting access to a wide range of frontline media and civic actors globally. There is an urgent need for technology platforms to play a role in facilitating increased access to methods for detecting manipulated media, yet it became clear through the workshop that the realities of adversarial attacks lead platforms to avoid widely collaborating with others on detection methods. The legitimate need for caution on the part of large technology platforms—important engines of synthetic media detection innovation—must be reconciled with the need to share detection capabilities widely, around the world.
Creating multistakeholder processes to deliberate and ultimately decide which actors are granted access is not only important for manipulated media detection tools, but also for search tools, training datasets, databases of previous verification results, and related items bolstering media verification efforts. Technology companies should continue to think about the benefits of limited release for datasets and tools, while recognizing their role in supporting actors in the broader information ecosystem. Further, they should follow a clear protocol and explain the logic of who they choose to prioritize as early users. Expanding access also requires complementing tools with media forensics capacity to ensure that such tools have a low barrier to entry and are appropriately used.
4. Can the tool detect deepfakes, cheapfakes, and misleading context?
Tool developers should consider the extent to which their tools can detect the spectrum of manipulated media, and whether they can incorporate additional contextual information. An ideal detection tool would not only detect AI-generated images videos, but also lower-tech manipulations including cheapfakes and altered or misleading context, such as false captions.
AI-generated images and videos (deepfakes) are only one type of media manipulation, and the bulk of current malicious manipulated content is produced using much simpler techniques (cheapfakes). At a minimum, detection tools should be able to detect subtle manipulations that do not require AI techniques. Several emerging detection tools already use an ensemble of models, including detectors for non-AI cut-and-paste image editing and video speed changes. Although AI-generated media is uncommon today relative to other other manipulations, we should prepare for its wider use as it becomes cheaper and easier to create.
Journalists at the workshop also expressed concerns about the ability to detect manipulations other than the face swaps typical of deepfakes or heavily-photographed public figures, like celebrities and politicians. For example, imagine a video where the weather in a video depicting troop deployment was manipulated. This could drastically change the perceived timing of troop activity, potentially reducing the power of visual evidence in investigations and conflict reporting.
Further, verification work must not only consider false content, but false context. Many of the fact-checkers in our workshop described making use of contextual clues to help evaluate whether or not the claims depicted or described in videos are accurate. A single numeric probability that a piece of content was manipulated, whether produced using AI or less sophisticated techniques, is unlikely to say anything about whether or not that content is misleading or can cause harm.
For this reason, some in the technical communities argue for greater investment in techniques for inferring authenticity, harm, and intent by using broader semantic context (such as the signals identified by the Credibility Coalition). It will be difficult for automated methods to gauge meaning with any degree of certainty, and the deployment of context-sensitive models presents unique ethical questions. However, harm and intent are critical judgements that humans try to assess. Detection tools should not merely show model output, but present useful metadata and contextual clues associated with the image or video to help with content judgments.
5. How do you explain the tool’s output to users?
Tools should present detection results in a way that media verifiers can easily interpret, and provide clarity on the confidence of such judgments. The models in manipulated media detection tools typically output probabilities, essentially just numbers conveying some degree of likelihood that the image or video is manipulated. In some cases there can be several probabilities, such as the probability of manipulation of each frame or for particular regions of the frame, the probability that faces have been swapped, or of other perturbations. Heat maps or other more sophisticated visual outputs may be more easily interpretable, but this has not been rigorously tested.
How should users make sense of these numbers and visualizations, especially those without specialist training in media forensics or statistics? What should they do when multiple models produce conflicting results? How tools present detection model output, and the extent to which they communicate potential error or uncertainty, is extremely important to the ultimate utility of such tools.
The output of detection tools is particularly high stakes, as verification professionals rely on trust and interpretation of the tool’s output to legitimize high-stakes claims that impact public opinion. In particular, there could be negative impact from presenting detection outputs designed for specialists to the public as evidence for the legitimacy or illegitimacy of a certain piece of media. If the explained tool output becomes substantiating evidence to promote trust in content, despite relying on imperfect detectors, this could sow confusion for audiences and ultimately damage media credibility. This issue is especially pressing due to the high false positive and false negative rates of state-of-the-art detection models.
Workshop participants identified one type of explanation that is clearly and widely useful: a verified copy of the unmodified original piece of content. While it is not always possible to locate the original media instance, it is a strong argument for developing provenance and matching infrastructure techniques.
6. How do detection tools fit into the broader media verification workflow?
While detection can provide a signal of whether a media item has been altered, that doesn’t necessarily translate to a signal of content authenticity. An image could be authentic and feature a caption that changes the meaning of that image and misleads viewers, or it could be manipulated but clearly satire or fiction. Machine learning models that try to detect manipulations by only examining content—the actual pixels of an image or video—can contribute to building the case that an item is misleading, but cannot substitute for human contextual judgment. This means that detection models must be integrated into broader media forensics workflows.
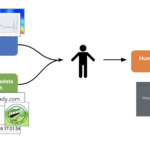
Detection tools cannot directly produce a decision on whether a media item is false or misleading. Instead, they are one signal in the human process of assessing authenticity, intent, and harm, and producing labels that are understandable by audiences.
The media verification community would benefit from responsible technical approaches to track the provenance of digital media as it moves from capture to editing to publication; such information could help bolster how media verifiers understand detection outputs. Provenance is also concerned with whether or not there are previously existing versions of the media. While reverse image search is a standard tool for verification work, verifiers are greatly in need of platform-scale reverse video search, as well as matching technology to help determine if an item has appeared previously. Doing so would not only help media verifiers gauge content authenticity, but also offer signals into when and how manipulations occur and shift verification from thinking in terms of a “whac-a-mole” model for detection of individual pieces of content to better understand the interrelation between pieces of content.
Where Do We Go From Here? Next Steps to Help the Media Verification Community
Tools are a critical component of the media defense against manipulated media, but detection tools alone are not enough to address the threats posed by manipulated media. Identified and vetted by Synthetic Media Detection Tools workshop participants, the six efforts proposed below would not only ensure the best use of existing detection models and technology, but also further contribute to the needs of the media verification communities around the world.
1. Develop threat and access models for manipulated media
“Until a threat model is adopted, it will be difficult or impossible for stakeholders to adopt technical tools.”
Manipulated media detection tools are vulnerable to malicious adversaries trying to outsmart them, which is much easier to do with access to the underlying detection techniques. This makes it necessary to simultaneously consider threat, adversary, and access models for such tools.
A useful synthetic media detection threat model will need to include a variety of complementary assessments including:
- Which adversarial actors are expected to have the capability and motivation to break a detection tool? Are they particular nation states, or perhaps private companies?
- What types of manipulated media are most common? Should we be most worried about face swapping, or synthetic speech, or perhaps various cheapfake methods?
- Where are adversaries most likely to deploy synthetic media? Should we be concerned about upcoming elections, or perhaps particular human rights issues?
- Conversely, who is most at risk from these threats? And who should be involved in defining the threat model?
A threat model is not only an estimate of the security situation, but also embodies judgement of who and what must be protected. It is therefore vital to include a globally representative and diverse group when modelling threats.
Without answering these above questions, it is impossible to design counter-adversarial strategies and think about how to responsibly grant access to such tools to the appropriate users. Such modeling efforts also help define the most useful problems that researchers should address. Any access regime will balance the adversarial nature of the threats identified with the need to ensure broader access to such tools.
There are many hybrid access strategies available that are not simply public access or total restriction. In our past work on the Deepfake Detection Challenge, the PAI AI and Media Integrity Steering Committee advocated for a hybrid release model, encouraging publication of papers and other materials discussing the winning methods while delaying the open release of code and models for a certain time, perhaps six months to a year. Meanwhile, trusted parties were to be granted immediate non-open source license to use the technology for their own work. This approach would deliver the eventual benefits of openness, while the lag would provide some detector advantage over those trying to generate adversarial synthetic content. At a technical level, access could be provided through a detector API that restricts the number of requests to some reasonable human level. This would prevent the automated training of detector-defeating generators even if someone were to gain unauthorized access—a near certainty for any tool that is globally deployed.
As a first step, the tool could be restricted to particular users, where only verified individuals and organizations get access. This raises the issue of who decides on access decisions, where a global, neutral, multistakeholder third party such as PAI could play a clearinghouse role.
2. Create tools to help assess provenance, including reverse video search
Finding similar videos is a key part of the media verification process today, and understanding original sources and artifact provenance can help provide insight into how a video or image has been manipulated. This also shows how the artifact has been re-used over time, which can reveal manipulations of contextual information such as changed captions.
Those at our workshop emphasized that providing access to a reverse video matching service—analogous to the existing reverse image search on Google—would be a major asset to the broader media verification community. Technology platforms have very large repositories of video and images and have experience matching near-copies or individual objects. For example, Facebook has models to find modified versions of images that were previously identified as misinformation during the COVID-19 pandemic, and YouTube’s ContentID is a digital fingerprinting system developed by Google which is used to identify and manage copyrighted content on YouTube. This sort of video and image matching against platform-scale data repositories would greatly assist journalists, fact-checkers, and those in civil society around the world in dealing with manipulated content online.
Understandably, platforms do not want to share all of their data, nor do they wish to be perceived as arbiters of content accuracy. However, future work should articulate the challenges to building such a system, including privacy, legal, security, and competitive considerations, and move towards production of an accessible reverse video search mechanism. This work could rely on the same threat and access considerations that would inform use and access to detection tools.
3. Define a standardized API for detection models
There are several teams currently building tools for media verifiers, while researchers constantly publish new techniques and models. However, participants identified the problem of rapidly deploying new detection models across the emerging tool ecosystem.
This is an issue for several reasons. Practical tools must include many different detectors which use different methods and look for different types of manipulations (ensembling, as described above). Each of these models is expected to have a limited useful life as adversaries figure out how to evade them, which means they will need to be replaced regularly. And although different users will prefer different tools, their choice should not lock them out of state-of-the-art improvements available elsewhere.
Workshop participants emphasized a need for a fast track from research code housed on GitHub to end-user deployment. A standardized API would define the interface between detectors and the tools that host them, allowing rapid deployment of new methods, instant extendibility of existing tools, and the creation of a library of methods that are collectively more robust than any one tool. This would be a win for researchers, users, and tool builders alike—even commercial tool builders, as the limited lifetime of detection models means that it will be difficult and expensive to maintain a competitive advantage based on proprietary detection technology; instead we expect competition to drive innovation in user interface, integration, services, and support.
APIs, like all standards, face a chicken-and-egg problem in adoption. Repackaging the models from the Deepfake Detection Challenge, which already all use a proprietary API developed by Facebook and Kaggle (the contest host platform), would be an intuitive place to start.
4. Continue research into audience explanations and labels for manipulated media
While the numeric probabilities that algorithms output are important for manipulated media detection, the way those probabilities are distilled and explained is just as critical. Many different stakeholders make use of algorithmic output: media verification specialists (such as media forensics specialists and fact-checkers) need to assess the authenticity of media, platform engineers need to use the output for automated triage of manipulated media, the media professionals need to communicate how they know an image is manipulated or genuine, and ultimately, the public needs to learn how to accurately identify and interpret how media has been manipulated. We must therefore invest in research and collective information sharing about how to communicate these results effectively to different audiences.
Different explanations of algorithmic output might be required for each of these stakeholders. How do we build models and tools with outputs closer to human-understandable labels? How do we communicate uncertainty, especially when the results of detection are inconclusive or conflicting? How do we address the risks of presenting detection outputs designed for specialists to the public? PAI has begun investing in work on how to label manipulated media for audiences, and we will continue to further research these and other questions related to how different stakeholders can best be communicated the results of algorithmic signals conveying content credibility online.
5. Create a centralized directory of manipulated media examples and detection benchmarks
Workshop participants strongly emphasized the value of creating a thorough reference database of manipulated media examples. It can be useful to reference previous media verification work for several reasons. One of the first steps in human media verification work is to search for previous copies; if a particular image or video has already been determined to be authentic or manipulated, much time is saved. Large collections of labeled media are also important resources for synthetic media research, for the creation and evaluation of detection tools, and for countering the spread of manipulated media at platform scale.
Many different organizations do media verification and fact checks, but there is currently no unified database of their completed work. Further, all of these organizations use different sets of labels or ratings (“four pinnochios” vs “pants on fire.”) Collecting all of this information into one place along with the articles and media items themselves, and harmonizing it would solve some key problems for multiple stakeholders.
If such a thorough database were created and appropriately accessible, fact-checkers, journalists and other verification professions could use it to answer the question, “has this already been seen?” Researchers could use it to study the real-world prevalence of various types and topics of manipulation, and to develop new detection methods. Tool builders could use these examples for training detection models. Platforms could use these examples both to train models for triage, and to automatically detect posted duplicates of previously debunked items—though the possibility of automated content removal raises some tricky issues. Standardized benchmarks created from this database would foster rapid progress in the detection research community.
There are several challenges with this idea, including access. If such a database were publicly available, malicious actors could use it to develop synthesis techniques that evade detectors. Such a repository could also become a resource for conspiracy theorists and extremists. As with detection tools, careful adversary modeling and access model design will be necessary.
6. Deepen investment in media forensics training
According to some workshop attendees, journalists lack a nuanced understanding of how and why manipulated media is created. They consider manipulated media detection to be a specialist’s job, rather than something they should be alert for throughout their reporting. The lack of both awareness and capacity will seriously hinder the ability of journalists, fact-checkers, and other media verifiers to combat malicious manipulated media, especially in smaller organizations. Without training, the global media ecosystem will remain vulnerable.
There are several plausible ways this training could be delivered. Journalism schools have a role to play, and should add expert guidance on current media forensics techniques to the curriculum. But many verification professionals do not go to journalism school, and in any case this does nothing for those already working. Thus, we must also look to on-the-job training.
There are several possible models for this. Reuters and Facebook now offer online deepfake training in 16 languages. This training offers valuable advice on standard verification procedures (e.g. contacting the original source of a video found on social media). It does not offer guidance to interpret the probabilistic results of technical detection, in part because technical detection is not yet widely available. More thorough training will probably require hands-on use of existing tools, and specific advice for using their outputs. There are several organizations which already have international experience training media professionals in technical skills, including WITNESS, Internews and IREX. These existing networks and programs can be leveraged to deliver global training, and ultimately build capacity at all levels of the media ecosystem.
Such training should include:
- The nature and scale of the manipulated media threat, as illustrated through examples
- How manipulated media detection fits into existing verification workflows
- Hands-on use of specific tools, including both contextual tools (e.g. metadata analysis, video search) and detection proper
- Best practices for interpretation of detection model outputs
- Issues surrounding manipulated media labeling and public credibility
It will be essential to involve experts from different fields in the creation of such a training program, including journalism, media forensics, machine learning, and mis/disinformation. Such a program will need to be significantly localized, including translation to different languages and curriculum changes to reflect local threats, infrastructure, and opportunities.
A Call for Work Beyond Detection: How to Manage Manipulated Media Tools as a Community
Technology platforms are both users and creators of detection technologies, but there are others in the media verification community, including journalists, fact-checkers, policymakers, and those in civil society around the world that need to be able to evaluate the veracity of information. While detection tools are one way to support these communities, there are related efforts and additional technical questions that must be pursued to ensure effective media manipulation mitigation efforts around the world.
The Partnership on AI continues to work on AI and Media Integrity challenges with the many stakeholders who must be involved in addressing these challenges—technology platforms, journalists, fact-checkers, mis/disinformation experts, media forensics trainers, computer vision researchers, and others. In doing so, we hope to help combat the impact of malicious media online and work towards bolstering the quality of online discourse around the world.
With thanks to: Participants in the Partnership on AI Synthetic Media Detection Tools Workshop Series, Rosie Campbell, the Knight Foundation, the Partnership on AI AI and Media Integrity Steering Committee






